頷くしかない
 SASANO Takayoshi(@uaa@social.mikutter.hachune.net)の投稿
SASANO Takayoshi(@uaa@social.mikutter.hachune.net)の投稿 OpenBSD(uaa@), Ham(JG1UAA), Ingress(Lv14, RES), Japanese(Sagamihara-city, Kanagawa)
Another side: https://social.tchncs.de/@uaa
npub1rarr265r9f9j6ewp960hcm7cvz9zskc7l2ykwul57e7xa60r8css7uf890
Messages from this Mastodon account can read via mostr.pub with npub1j3un8843rpuk4rvwnd7plaknf2lce58yl6qmpkqrwt3tr5k60vfqxmlq0w

日航123便事故は #TRON を潰すための陰謀、みたいなステキな話を聞いてへそで茶が沸いている。一般に支持されそうにないことを言い出す前に、TRONを再興すべくコードの1行でも書いたらどうだ?
default_options.h:#define DROPBEAR_X11FWD 0
う、うがああああああああああ(dropbearでいくら頑張ってもX11 port forwardingができないのはビルド上の問題だったなんて…っ!)
まあ、コードも書かず口だけの人達は相手にしない(用があるならGitHubのリポジトリにIssueなりPRなり投げなよ)というスタンスで「例の件」を扱うことにします。今までも、これからも。
TRONフォーラムも123便の件はだんまりというか無視し続けてるけど…きちんと否定するもんは否定しないとやられてく一方っていう認識を持ってないような気がする(持ってたらすでに手を打ってるだろうし)。
ボロクソに言われてるコミュニティにわざわざ近づいてコード書いてなんかしたろ、というのは相当の物好きか阿呆(口悪くてすまん)のやることで、普通の人間は近寄らないでしょ。「あの人あの○○に関わってるんですってヒソヒソ」って言われてしまうような、自分自身の価値を下げに行く必要は無いのだし。
別に隠す必要も無いけど大っぴらに話すもんでもないし、とはいえ伏せたままだと不具合も増えてきたんじゃ少しは匂わせとくかという…面倒な立ち回りを求められても正直困る。
メーカーの製品ならそれに関わるコミュニティの運営だの印象制御だのといった諸々はメーカーのお仕事でしょうに。
例のアレはX側にもクロスポストしちゃってるけど、正直あんまりやりたくないんだよね。ヘンなのに絡まれそうなんだもん。
とはいえ、黙ったままでいるとヘンなのが調子付いて余計に面倒なことになるから、牽制のつもりでネタを渋々振ってるというのはある。
https://twitter.com/uaa/status/1716030288164495613
これでもオブラートに包んでいるつもりなんだけど、もう一段表現をエスカレートしないとダメなのかなと悩んでいるところ。一応、こちらの事情としては
https://twitter.com/uaa/status/1258475269360214018
からお察しくださいなということで。
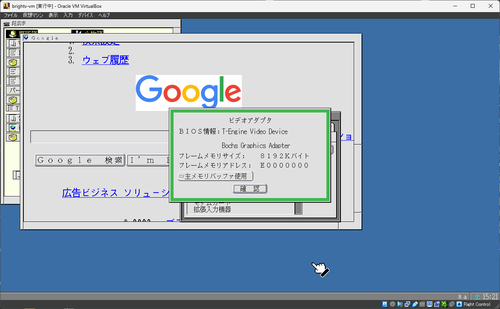
あっははは、vmxscreenのBGAドライバにバグみっけ。
bochsのレジスタI/O、16bitにしないとVirtualBoxではちゃんと動かない(bochsだと動いてたのか…)
まあ今すぐであれこれはできないけど、ちょっと気にかけておこう…
https://wiki.osdev.org/User:Kazinsal/VirtualBox_Video_Adapter
VirtualBox VGAはBochs派生っぽいのでBochs用ドライバに手を入れると良いのかな?
VMware SVGA互換を持ってるみたいなのでそれを使ってみたけどvmxscreen動かないな…
drm/vboxvideo見ながらちょっとvmxscreenいじってみる…? https://github.com/torvalds/linux/tree/master/drivers/gpu/drm/vboxvideo
VMware Player上の超漢字V仮想マシンをVirtualBoxへ持ってきた(といってもディスクイメージだけでマシンの設定は書き直した)んだけど…vmxscreenが0x80ee 0xbeefなPCI videoに非対応なのでこのドライバを書かないと画面が何も出ないっす。
あとUSBもOHCIなので、起動時のInitUsbMgr ER_SYS[0]ということでUSB自体が使えなくなってる。ネットワークはAm79C973(Pcnet-FAST III)として見えてるので一応動く。
昨日インストールして即アンインストールしたVirtualBoxを再インストールしてみる。
(なので、SKK辞書との併用をしないと使い勝手が極めて悪いんですよね…)
EUC-JP環境で「も」動かす予定があるかどうかで決めるのが良いのかなあ。Unicode辞書にしてしまうと、EUC-JPでは結果を正しく扱えないという事態が起こってしまうし…
(実はnwc2010-libkkcはその辺を厳しい方向に振っていて…流石にCJK統合漢字の日本語のみ通すといったことはしていないけど、英数字や記号類は候補として一切認めていなかったりする)。

内部エンコーディングをEUC-JPのままにした方が手間は減るけどUnicodeネイティブ世代からすると辞書に登録できる文字に制限ができるという面もあり、悩ましい
sj3のUnicode対応もどうしたもんだろうね?(ちゃんと見てないのでテキトー書いてるかも)EUCな辞書をSJISに変換したりとかしてる感じがあるので、だったらUnicodeもEUCから変換/UTF-8化まで自前でやるかという話になるんだろうか。
それとも、辞書レベルでUTF-8からやっちゃうというのもあるんだろうけど…多分内部構造を大幅にいじらないと厳しいんじゃないかなあ。
(しばらくLCDパネルをいじってたのでsj3関連はお休みしてましたが、そろそろ戻らんと…)
当然っちゃ当然と言われそうなんだけど、Vine 2.5上でビルドしたsj3はこんな風に動いてる。キーバインドとか全然慣れてないのでロクに文字入力できないけどね…
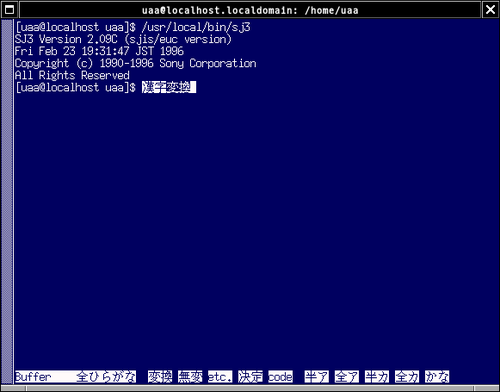
sj3(tty上でかな漢字変換する方)、OpenBSD上で動かすよりもまずはLinux上で動くモノを手にすることから考えるか…なにしろ未だにUSE_OLD_TTYなるものがよく分かってない。
gcc -o sj3 -O2 -m486 -fno-strength-reduce -L/usr/X11R6/lib sj3ver.o version
.o sj3.o funckey.o term.o sjgetcha
r.o conv.o stat_conv.o henkan.o romaji.o display.o code.o
etc.o toroku.o edit.o eucmessage.o douon.o
sjrc.o kigou.o common.o screen.o libif.o rk_con
v.o sj3_rkcv.o wc16_str.o nmttyslot.o ../sj3lib/libsj3lib.a -ltermcap
Kanconvit.pm、web archiveから引っ張って来れると…これは言えるのか?(なんか強引に引っ張ってきたとしても文字化けしてそう https://web.archive.org/web/20090712040042/http://kanconvit.ta2o.net/Kanconvit.pm
VMware Player→VirtualBoxへのV2Vどうすんのと思ってたけど、VMware Open Virtualization Format Tool使うしかないのかな(vSphereだとOVFへのエクスポートができるけどPlayerではできないみたいだし)。 https://developer.vmware.com/ja_JP/tool/ovf/4.1.0
光学ドライブ無くてもUSB接続のがあるからいいもんね→駄目でした(なんか動作が安定しないので、光学ドライブが内蔵されたマシンの支援が必要でした)
@hfp halt、rootだとそのまんまで通るんですがsuで化けた場合は/sbin/haltで指定しないとマシンを落とせないんですよ…もうなんかどこのマシンでも/sbin/haltで落とすようになっちゃって。
(Slackwareも、rootだとビルドに失敗するけどユーザーだとうまくいくとか、なんかroot/userの区分があるのかも)
@hfp どうなんだろう…でも確かに、rootログインした場合と、suで化けた場合とでパスの通り方が違うとかはあったような。

「学校」を何でもできちゃう『夢の巨大実験場』にしたい!!【すしらーめんりく】 - CAMPFIRE (キャンプファイヤー)
https://camp-fire.jp/projects/view/714499
プール改修ステージに行っててワロタ

suでrootに化けた後に/sbin/dpkg-reconfigureするのと、sudo dpkg-reconfigureするので、何が違うんだろう?後者じゃないと動かないケースに遭遇しちゃって。
これからどうしろと…(自局間通信禁止により自分のところのXLXサーバも使えず、BrandMeisterのIPv6対応もなくなっているようなのでMMDVMHostのIPv6対応コードをどうテストすれば良いのかと途方に暮れている)。
どこにログインできるのか探すのに一苦労とかそんな状況。まあPi-Starみたいなオールインワンパッケージ使うならラクなんだろうけどね。
久々にMMDVMHostを起動してBrandMeisterへ繋げてみたけど、Master(サーバ)の稼働状況が変わっていて今まで使ってたIPアドレスが結構使えなくなっていたのが驚き。
来年こそどこかの新聞社とかどこかのTV局の断末魔の一つや二つを聞きたいですね。
…いい加減、待ちくたびれましたよ?

このアカウントは、notestockで公開設定になっていません。
トイドローンのバッテリーの充電→おわった
無線機の充電→あと2台残ってる
フル充電しているはずなのに飛ばして15秒程度で低電圧警告→墜落っていうのは、バッテリーに問題りと判断せざるを得ないんだが…
702030なバッテリーもあるけど、本当に7mm×20mm×30mmでHS210Proのバッテリーケースには全然収まらなかったという。どうすんのこれ…というのが未だに続いてる。
HS210Pro用のバッテリー、型番はFB752030になってるけど、サイズを見るに801530辺りになる感じ。300mAhじゃなくなるけど、801525(230〜280mAhくらい)という選択肢もあるのかも。
MITになってる https://github.com/takp/kanji_chinese_converter を使うか、あるいはその原典たる http://kanconvit.ta2o.net/ (internal server error出てるのでX経由で連絡してるけどどうなるかなー?)に当たるのが良いのかもという結論に。Unihan-2.txtのkうんたらVariantを利用するのは止める方向で。
やっぱ先人の成果を利用する方が良い結果になるはず。
円(U+5186)/kZVariant→圓(U+5713)/kSimplifiedVariant→圆(U+5706)まで繋がないと円→圆の変換はできないんだけど、どうしたもんだろう。
kTraditionalVariantだけでなくkZVariantも見るようにして、こんな感じ。とはいえ、他の文章を表示させるとまだまだ〓を見ることはあって。
でもこんな感じのものが欲しい、という部分では一歩進んでる。
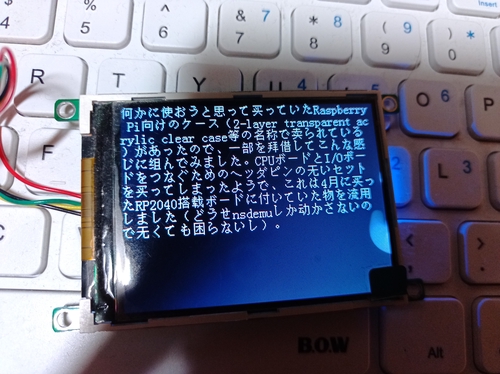
LCDパネルの仕様を見るに、GB2312と書いてあったのでGBK対応の可能性はきわめて低いと判断。8192文字云々ともあったので、流石にGBKではないと思う。
そうか、GB2312ではなくGBKが通るかどうかで対策が変わってくるな。GB2312ではどうにもならなくても、GBKに拡張できれば望みがある。 https://www.antenna.co.jp/ml/back/Chinese/gb_charset_memo.htm
Unihan-2.txtによる補正と、一部記号類を強引に置き換えて多少は読めるようになったけど(無→无は日本人として違和感あるけどしゃーない)、まだ完全な置き換えにはなってない。「売」「拝」が出てない。
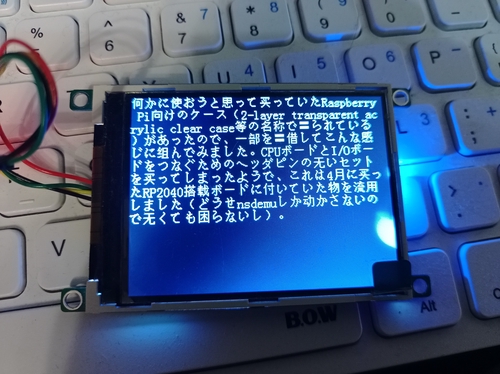
とりあえず、日本語のテキストをGB2312しか通らない中国製のLCDパネルでなんとなく(簡体字を使ったとしてもそれっぽく)表示する、という目的をなんとかしたいところ。サブ画面でちょっとしたメッセージを表示するのに便利そうなんだもん。
単にツイ廃向け液晶モニタを買う金が無い、ともいうけどw
でもUnicode 2.0のUnihan-1.txt、壊れてるよね。2.1のUnihan-2.txt https://www.unicode.org/Public/2.1-Update/Unihan-2.txt の方が良さそう。
https://android.googlesource.com/platform/external/python/cpython3/+/refs/heads/main/Tools/unicode/python-mappings/GB2312.TXT を使ってUCS→GB2312変換テーブルは作っちゃいるけど、これを https://www.unicode.org/Public/2.0-Update/Unihan-1.txt にあるkTraditionalVariantを使ってで繁体字→簡体字変換を入れるという方法で対処できるのかな。
逆にGB2312は簡体字なのでkTraditionalVariantが多い…
kTraditionalVariantの示す先(繁体字)へのアクセスがあった時に、に対し、その(簡体字の)コードを渡すことで、繁体字をとりあえず簡体字として表示させるということが可能になる…で、いいのかな。
基本的には、日本語は繁体字のようなものということになるので…kTraditionalVariantよりもkSimplifiedVariantの修飾が付いてることの方が多そうに見えるな。
日本語でもkTraditionalVaiantが付く場合があって、U+4E07(万)に対するkTraditionalVariantがU+842C(萬)。
当然(?)、U+842CのkSimplifiedVariantはU+4E07。
uaa@framboise:~$ grep kSimplifiedVariant Unihan.txt |wc
2675 8032 88334
uaa@framboise:~$ grep kTraditionalVariant Unihan.txt |wc
2594 7868 88808
uaa@framboise:~$
「何か」(多分繁体字)に対する簡体字
「何か」(多分簡体字)に対する繁体字
の関係が一対一でないってことなのかなあ
jis2gb、コードをよくよく見るとライセンスの記載が無い…
これは流石にテーブルを使わせて頂こうにも、できないや。
Unihan1.txt読んでガンガレ、ということになるか。
jis2gb、これですよこれ…こういうの探してました(jis2gb2312じゃ見つけられなかった訳か)。 http://kanji.zinbun.kyoto-u.ac.jp/~yasuoka/program.html
邪魔の入らない状況でYoutubeなどを視聴できる環境は基本的人権だと思う…
今はYoutubeライブ見てるのでまだ実害は少ないけど、課金してみるタイプのオンラインセミナーでこれやられたら致命的。
カナル型のイヤホンを付けているにも関わらず、ガキ共の声がうるさすぎてYoutubeの音声が聞こえない…密閉型のヘッドホン買わないともうダメかもしれん。
繁体字と簡体字と日本語を区別する (2018-05-30) https://qiita.com/Saqoosha/items/927e9d6e77922ad9f08a
unihan database越しに引っ張る手もあるのか。そっちの方が良いか…?

xiaoyjy/cconv A iconv based simplified-traditional chinese conversion tool https://github.com/xiaoyjy/cconv
iconvで繁体字/簡体字の変換ができるなら…CJK unifiedで拾えない物に関しては繁体字経由(?)で簡体字を拾っていくって作戦はどうなんだろう。
中国製品にある怪しげな日本語っぽいアレって、こうやって作っていくのか…というのをなんか地で行っている気がする。
@hadsn それがあるから強引に表示できるのでは…と考えてしまいまして(ダメなら即座に諦めてました)。
繁簡對照表 (web archive, 2004/11) https://web.archive.org/web/20041011004638/http://cdns.twnic.net.tw/cjktable/
GB2312 Tutorials - Herong's Tutorial Examples https://www.herongyang.com/GB2312/
Reference Citations in 2004→GB2312 and Unicode Mapping Table http://herongyang.com/Reference-Citation/2004-GB2312-and-Unicode-Mapping-Table.html


Chinese-Japanese Machine Translation Exploiting Chinese Characters (Chu, Chenhui; Nakazawa, Toshiaki; Kawahara, Daisuke; Kurohashi, Sadao, ACM Transactions on Asian Language Information Processing, Volume 12, Issue 4, 01-Oct-2013) https://repository.kulib.kyoto-u.ac.jp/dspace/bitstream/2433/179788/1/2523057.2523059.pdf
やっぱ日中の漢字の変換って学術レベルになる話なのか
Chinese Characters Mapping Table of Japanese, Traditional Chinese and Simplified Chinese (Chenhui Chu, Toshiaki Nakazawa, Sadao Kurohashi, LREC conferences 2012) http://www.lrec-conf.org/proceedings/lrec2012/pdf/306_Paper.pdf
JISで書かれたものをGB2312でどこまで表示できるか試しちゃみたんだが…微妙だな…
kakasi使ってひらがなの量を増やす(漢字を減らす)というのが良さそうに思えるけど、それでもどこまで迫れるだろう。
あとは、漢字の類似度に合わせて強引な置き換えとかそういうのを考えないといけないけど、そういうのってもう誰かがやってたりするよね?(やっててほしい)
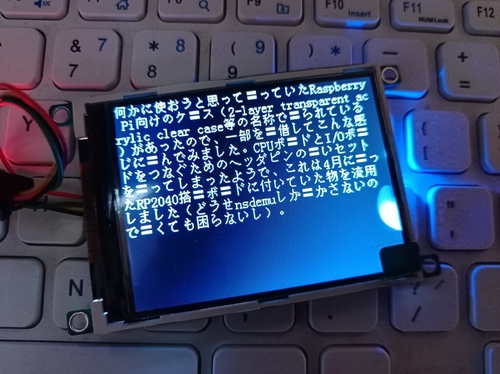
Unicode、CJK漢字を統合していることが非難されているという事情はあるものの…逆にこれを利用して、JISコードで書かれたものをある程度GB2312とかKS C 5601で表現するという目的に利用することができるのではないか?と考えている(テーブルを作れば良いだけなので試すのはそんなに苦労しないはず??)