Pentium G4600がターボ無しの3.6GHz動作、そもそもOpenBSDはターボ効かないので…となるとi7-7700(3.6GHz, turbo4.2GHz)しか乗り換え先が無いような。
以前i7-7700買ったときは\18kくらいはしていたから、今の\13k前後というのは多少下がった感じがあるけど簡単に手の出せる値段ではないなあ。i5-7500/7600辺りで妥協するのもやむなしかも。
 SASANO Takayoshi(@uaa@social.mikutter.hachune.net)の投稿
SASANO Takayoshi(@uaa@social.mikutter.hachune.net)の投稿 OpenBSD(uaa@), Ham(JG1UAA), Ingress(Lv14, RES), Japanese(Sagamihara-city, Kanagawa)
Another side: https://social.tchncs.de/@uaa
npub1rarr265r9f9j6ewp960hcm7cvz9zskc7l2ykwul57e7xa60r8css7uf890
Messages from this Mastodon account can read via mostr.pub with npub1j3un8843rpuk4rvwnd7plaknf2lce58yl6qmpkqrwt3tr5k60vfqxmlq0w
Pentium G4600がターボ無しの3.6GHz動作、そもそもOpenBSDはターボ効かないので…となるとi7-7700(3.6GHz, turbo4.2GHz)しか乗り換え先が無いような。
以前i7-7700買ったときは\18kくらいはしていたから、今の\13k前後というのは多少下がった感じがあるけど簡単に手の出せる値段ではないなあ。i5-7500/7600辺りで妥協するのもやむなしかも。
OpenBSDで使う分なら別にPentium G4600でも関係ないねって気がしなくもないけどどうなんだろう。やっぱAVX必須な場面は…まあ無くは無いんだけどさあ。
(お値段とCPU交換の手間次第なんだよな)
x86_64のサブバージョンが登場した話 (2021/05/05) https://qiita.com/lighthawk/items/e5b1dbb1a296ded68f57
Pentium G4600はx86_64-v2か。AVX/AVX2持ってないのでv3で来られちゃうと対応できなくなるね。
i7-7700とかi7-6700辺りの中古を仕入れとかないとダメなのかなあ(ちょっとこの辺の中古CPU買うのは怖いなーって思ってる、既に一個は使っていて今のところ問題は無いけどさ)。

元の文字列
abcdefghijklmno
BSで消された文字を大文字にすると
→BS
abcdefghijklmnO
BS
abcdefghijklmnO
←BS
abcdefghijklmNo
←←BS
abcdefghijklMno
←←←BS
abcdefghijkLmno
←←←←BS
abcdefghijKlmno
←←←←←BS
abcdefghiJklmno
←←←←←←BS
abcdefghIjklmno
←←←←←←←BS
abcdefgHijklmno
←←←←←←←←BS
abcdefGhijklmno
←←←←←←←←←BS
abcdeFghijklmno
←←←←←←←←←←BS
abcdEfghijklmno
←←←←←←←←←←←BS
abcDefghijklmno
半角文字だけ打ち込んでいる場合はマトモな動作になっているように見える…
元の文字列
aあbいcうdえeおfかgきhくiけjこ
BSで消された文字をカタカナ/大文字にすると
→BS
aあbいcうdえeおfかgきhくiけjコ
BS
aあbいcうdえeおfかgきhくiけjk
←BS
aあbいcうdえeおfかgきhくiケjこ
←←BS
aあbいcうdえeおfかgきhクiけjこ
←←←BS
aあbいcうdえeおfかgキhくiけjこ
←←←←BS
aあbいcうdえeおfカgきhくiけjこ
←←←←←BS
aあbいcうdえeオfかgきhくiけjこ
←←←←←←BS
aあbいcうdエeおfかgきhくiけjこ
←←←←←←←BS
aあbいcウdえeおfかgきhくiけjこ
←←←←←←←←BS
aあbイcうdえeおfかgきhくiけjこ
←←←←←←←←←BS
aアbいcうdえeおfかgきhくiけjこ
←←←←←←←←←←BS
aあbいcうdえeおfかgきhくiけjこ
←←←←←←←←←←←BS
aあbいcうdえeおfかgきhくiけjこ
でもさ、スラドはともかく「OSDNやめます→やめません」なんてグダグダをやられた以上、安心してOSDNなんか使ってられるか💢という人の方が多いんじゃないのかな?
冷えたLiPo電池は性能が出ないって以前ドローンの人から聞いたことがある
https://www.drone-station.net/blog/?p=1001
厳冬期におけるリポバッテリー取り扱いの注意点 (2019.2.19)

「蟹の精神」ってなんぞ…?と思ったら、「強さ、忍耐、順応性」ということらしい。 https://www.realtek.com/ja/about-realtek/realtek-in-brief

このアカウントは、notestockで公開設定になっていません。
元の文字列
あaいbうcえdおeかfきgくhけiこj
BSで消された文字をカタカナ/大文字にすると
→BS
あaいbうcえdおeかfきgくhけiこJ
BS
あaいbうcえdおeかfきgくhけiこJ
←BS
あaいbうcえdおeかfきgくhけiコj
←←BS
あaいbうcえdおeかfきgくhケiこj
←←←BS
あaいbうcえdおeかfきgクhけiこj
←←←←BS
あaいbうcえdおeかfキgくhけiこj
←←←←←BS
あaいbうcえdおeカfきgくhけiこj
←←←←←←BS
あaいbうcえdオeかfきgくhけiこj
←←←←←←←BS
あaいbうcエdおeかfきgくhけiこj
←←←←←←←←BS
あaいbウcえdおeかfきgくhけiこj
←←←←←←←←←BS
あaイbうcえdおeかfきgくhけiこj
←←←←←←←←←←BS
アaいbうcえdおeかfきgくhけiこj
←←←←←←←←←←←BS
あaいbうcえdおeかfきgくhけiこj
全角/半角/全角…の順じゃなく半角/全角/半角…の順にした場合にどうなるかというのは明日やります(めんどいんだもんこれ)。
あと、最後の一文字の入力に対してのみ「ローマ字かな変換」レベルでのBSが効いちゃうの、おぢさんはこれは好きじゃないんだけど。たとえば
「もじへんかん」→「もじへんかn」→「もじへんか」→「もじへん」→「もじへ」
って感じの動作ね。
「もじへんかん」→「もじへんかn」→「もじへんか」→「もじへんk」→「もじへん」→「もじへn」→「もじへ」
までやるっていうなら理解できなくもないんだけど(実装はえらく面倒そうだな?)。
元の文字列
あいうえおかきくけこさしすせそたちつてと
BSで消された文字をカタカナにすると
→BS
あいうえおかきくけこさしすせそたちつてト
BS
あいうえおかきくけこさしすせそたちつてt
←BS
あいうえおかきくけこさしすせそたちツてと
←←BS
あいうえおかきくけこさしすせそタちつてと
←←←BS
あいうえおかきくけこさしすセそたちつてと
←←←←BS
あいうえおかきくけこさシすせそたちつてと
←←←←←BS
あいうえおかきくけコさしすせそたちつてと
←←←←←←BS
あいうえおかきクけこさしすせそたちつてと
←←←←←←←BS
あいうえおカきくけこさしすせそたちつてと
←←←←←←←←BS
あいうエおかきくけこさしすせそたちつてと
←←←←←←←←←BS
あイうえおかきくけこさしすせそたちつてと
←←←←←←←←←←BS
あいうえおかきくけこさしすせそたちつてと
←←←←←←←←←←←BS
あいうえおかきくけこさしすせそたちつてと
なんか←を1回押しているのに、←2回押されたような挙動になってるよね?
敵の敵は味方、じゃないけど…「本当に許せないもの」を潰すためなら「許せないけどやむを得ないもの」は潰さずにおいておくという必要もあるんだろうね。
通信会社と結託して、NHKのコンテンツを見るならこのデバイスと回線で…とやってくる可能性を懸念してる。可能性は低いだろうけど。
難しいですね…NHKのネット上での活動を認めてしまうと、ネットにつながるなら受信料寄越せという未来が待っているので個人的には認めたくないという立場なんですけど。
とりあえず、一般人民における自由な情報の流通や情報の保持の権利について、マスコミはこれを否定したいという立場を取っていることは確かそうなので…こういう連中に対して我々はどう振る舞えば嫌な思いをさせることができるのか、というのは真面目に考える必要がありそう。

このアカウントは、notestockで公開設定になっていません。
(もしかして、sj3の表示回りってcursesで書き直した方が良いってやつなのでは…今それをやってしまうと多分何も片付かなくなるので置いておくけど、将来の誰かにお願いしたい案件になるのではという予感が、なんとなく。)
realmode_power_offだけあれば良い(power_offは無くても電源は切れる)
やっぱshutdownで仮想マシンがちゃんと落ちる(電源が切れる?)のはありがたい…実は今まで仮想マシンの電源を切る、という操作をやってたもんで。
Vine 2.5 on VirtualBox、カーネルオプションにapm=power_off,realmode_power_off(特にrealmode_power_offが重要)を入れないと電源切れないや。
参考:Shutdownコマンドで電源断とならない問題の対処方法 (30 Nov 2003) https://www.express.nec.co.jp/linux/distributions/knowledge/system/shutdown_error.html
JISX0213(所謂第3,4水準漢字)用bdfフォントのページ、wayback machineにあるこれ→ https://web.archive.org/web/20141006232653/http://www12.ocn.ne.jp/~imamura/jisx0213.html ではなく今でも生きているページってありますかね?
ほほーう、jisx0208.1990はk14goth.pcf.gzっすか。おそらくjisx0208.1983はk14-oldkanji.pcf.gzと。んでもって(Vine-2.1用だけど) http://ftp.vinelinux.org/pub/Vine/Vine-2.1/i386/Vine/instimage/usr/X11R6/lib/X11/fonts/japanese/ にファイルがそのまんまの形で転がってる。
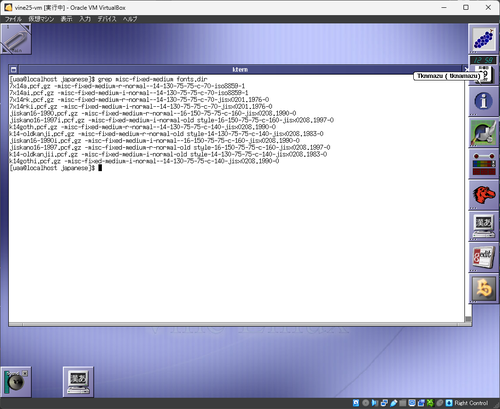
※行き詰まったのでフォントいじりをして現実逃避中※
-misc-fixed-medium-r-なフォント、jisx0208.1983だと明朝っぽいひらがなになるのに対し、jisx0208.1990だと柔らかい感じのひらがなになる。後者の方が好みなんだけど、これをどうOpenBSD上に持っていけばいいのかな…
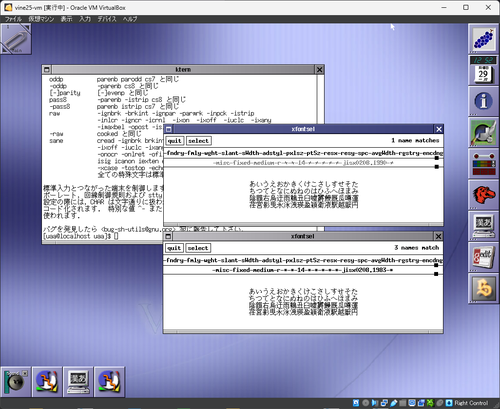
でもそこじゃなさそうだな。BuffYes()だのBuffModeだのを見てるとこ、の方が怪しいのかも。
@hadsn フリー版Sj3のドキュメントって見たことが無いんですが、もしかしてソースと最低限のビルド方法だけ公開して放置されてたりします…?って気が。(当時ならNEWS/sj3使ってた猛者が何とかしてくれるだろう的な空気でもあったのだろうか)
んむぅ、edit.cのexec_edit()の処理に何か問題があるんだろうなーという気はするんだけど、(例のfor()の後を{}で括るべきなんじゃないんですかね?というのもここにある)、何をどうすると問題になるのかがいまいち想像できぬ…
@hadsn 説明書があるだけマシじゃないですかSj3なんて説明書すらないんですよ…(多分NEWS付属のはあったんだろうけど)
sj3で、buffer modeの時にBSキーで確定してしまう(Ctrl-Hは大丈夫)というのは多分mlterm/xtermの問題な気がする。kterm上だと問題ない。ssh越しかどうかは関係なくなった。
当時物の原典からしてコレ、というのはどういうことなんだい…???
BSキーを押した後にEnterで確定すると、「あいうえおあいうえおあいうえおあいえお」となっている…表示がめちゃくちゃなのと、←, BSの操作なら最後は「あいうお」になるはずなのに「あいえお」になっているのが謎。
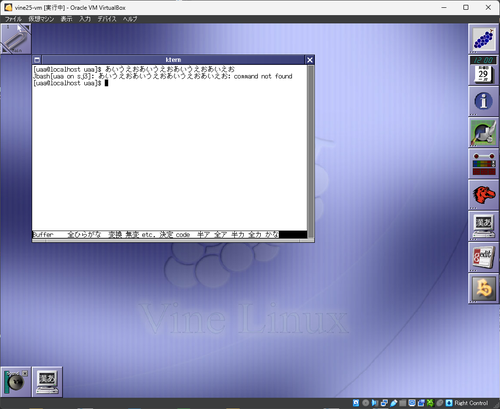
その状態でBSキーを押すと、入力した文字列がやたらと短くなっている
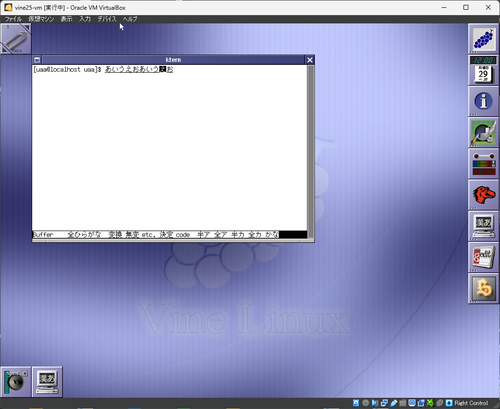
この時点で左のカーソルキーを一回押す。何故かカーソルは左から二つ目の「お」に来る
(先ほどのスクリーンショットの厳密な続きにはなっていないのですが、何度やってもこうなります)
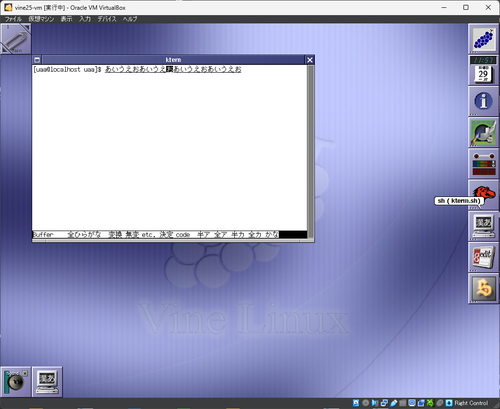
sj3(tty client)を起動し、バッファモードで「あいうえおあいうえおあいうえおあいうえお」と入力する
カーソルの位置は一番最後の「お」の直後
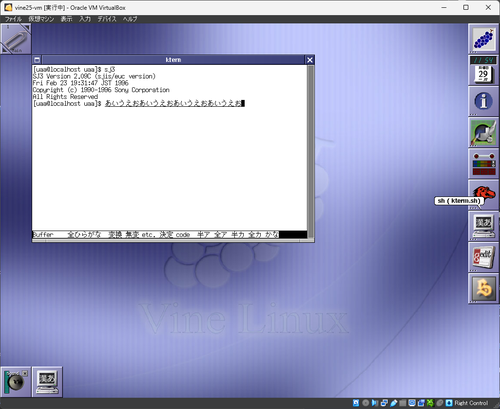
うーん、なんとなくだけどktermで使え、という気がするんだよな。あるいはkon。fbtermはds/fsのエントリ無し。
ktermのUTF-8版とか、あるはずだと思うんだけど普及(?)してるのかなあ。
/etc/termcap、
xterm+sl|access X title line and icon name:\
:hs:\
:ds=\E]0;\007:fs=^G:ts=\E]0;:TS=\E]0;:
なんてのがあるくらいなのでおそらくデフォルトのxtermはステータスライン(ds/fs)は非対応。ktermはds/fs装備済なのでってことで。
ふーむ、buffer modeにおけるカーソル/BSの挙動が全般的に怪しげ、という理解。
GoogleブックスのLinux日本語環境、xclipboardのスクリーンショットの中にもkanjihandの名前が出てるんだけど(ってGoogleさんそこ認識するんですか…!) https://books.google.co.jp/books?id=0uTiYB_rMDQC&pg=PA215&printsec=frontcover&dq=kanjihand&newbks=0&hl=ja&ovdme=1&redir_esc=y#v=onepage&q=kanjihand&f=false
当時の日本語環境の歴史を知る上で、この本を押さえておくべきなんだろうか。
BSD256倍本買っといて正解だったかも。KanjiHandとかWorld21なる、日本語表示環境があることを知ることができたから。とはいえ、ぐぐったところで
http://x68000.q-e-d.net/~68user/unix/pickup?KanjiHand
http://x68000.q-e-d.net/~68user/unix/pickup?World21
http://ukai.jp/Articles/1993/sd-pc98unix.txt
その存在があったことくらいしか知ることはできないようだ。
「神奈川県のアレ」って何を指してるんだろう。なんか色々ありすぎて…
b.の採用もなくはないか…4byte目までデコードしたけどそこで打ち切り、次から表示ね、という動きになるなら。
問題は不正なコードを食らった場合の処理なんだけど、どうすれば良いんだろう。6byteで1文字を構成するとして…4byte目が不正だったら…
a. 1~3byte目を棄却して4byte目から吐き出す
b. 1~4byte目を棄却して5byte目から吐き出す
c. 6byte全部を棄却する
d. 6byteを丸ごと吐き出す
※棄却した場合は〓とか表示して異常があったことを示す
のどれかにはなりそうなんだけど。
(a.は4byte目のデータを信用できる場合、b.は信用できない場合…おそらく多少信用できないデータでもなんか吐いといた方が分るだろうという判断で、b.を採用するケースは低い気がする)
やっぱこの対応が自然ですよねえ。
「4バイト以上の文字は現状のTera Termでは表示できないが、デコードだけでも正しく行うべき。」(2009/6/18)
https://ja.osdn.net/projects/ttssh2/ticket/17228
Oracle寄りだとCESU-8の絡みもあって、UTF-8は6byteでーすと書くしかないんだろうか。
文字化けについて (2023.10.17) https://www.reqtc.com/column/post-11.html
とはいえ、自分のこのポストに対して「CESU-8とUTF-8は違う!💢」と石が飛んできそうだ。
https://www.wdic.org/w/WDIC/CESU-8
https://www.unicode.org/reports/tr26/tr26-4.html
SIMD命令を用いるUTF-8文字列デコード処理の高速化(情報処理学会論文誌 プログラミング Vol.1 No.2 Sep 2008) https://cir.nii.ac.jp/crid/1050564287843900160
ベクタ演算で高速化できるのは良いけど、不正なコード食らわせた場合にどういう動きをするのかは気になるところ。予めクリーニングしてからデコードさせるのかなあ(だとしたらクリーニングのコストはどうなる…)?
日立の(何かの製品の)UTF-8変換だと、未定義というか不正な文字コードに対しては半角スペースなり#(全角の#)なりを吐き出せるようになってると。 https://itpfdoc.hitachi.co.jp/manuals/3020/3020657500/W5750016.HTM
不正なコードは変換せずスキップというのは…そのまま吐き出す、ってことで良いんだろうか。 https://itpfdoc.hitachi.co.jp/manuals/3020/3020636230/W3620027.HTM
ん-、CESU-8だのRFC2279の5~6byte UTF-8を食らった場合はどう対応するのが適切なんだろう。現在のRFC3629非準拠なものには対応しない、おかしくなっても知らんがな、で良いならそうするけど…その差異をセキュリティホールとして突かれる可能性があるなら、考えないといけないし。
UCS-2←→wchar16_t変換テーブルのジェネレータ、一応こんな感じ。 https://pastebin.com/raw/cZXjnifj
Debianのiconvってなんだかよく分からないんだけどC1 control領域(U+0080~U+009F)に対してよく分からない変換をしてくれるので外しておく必要があるのと、private領域(U+e000~U+f8ff)もなんかよく分からない変換をしてくれるので(ry
サロゲート領域(U+d800~U+dfff)については嫌な予感がしたので最初から変換対象に入れてません。
nwc2010-libkkcを直して(mappingの影響範囲はこんな感じ https://github.com/jg1uaa/nwc2010-libkkc/commit/14f6e66ecd27c04572ebdf1ceb1e4243b1768183#diff-48b245bdedad582320549b593c4a9b59b83f11d116cd81005b46f2ff5764d8c7 )とりあえずiconv()によるUCS2/JIS変換の評価はおしまい。
これをベースにsj3用のwchar16_t/UCS2変換を作れば良いかな(というかwchar16_t/UCS2変換が先だったりするんだけど)。

JIS0208.TXT(obsolete)なUnicode/JISマッピング対応表を使うのを止めて、iconv()での変換結果から対応表を作ってみたけど、JIS0208.TXTの結果とそう変わらない(\~の部分が若干違う程度な)ので今後はiconv()を使うことにします。
というかフツーiconv()で変換してますよね…?
出先だったんですが、揺れましたねえ。あれで震度3…
そういえば、不正なサロゲートペアの組み合わせってどう処理されるんだろう。たとえば
上位サロゲートの後にサロゲートでないUCS-2が続く
下位サロゲート・上位サロゲート(順番が逆)
下位サロゲートのみ(上位サロゲートが無い)
なんてケースもあるはずで。
こういう時に、不正なので取り除くのか、不正っちゃ不正なんだけどなんかあるので残しておくけど無視するのかというどっちの対応が適切かというのは問われるよね(そして仕様書にはどうすべきか記載があると思うんだ…読めよ>自分)
ふと思ったけど、iconvでEUC-JP/UCS-2テーブルを作った場合、そのテーブルのライセンスって何になるんだろう。JIS0208.TXTを使った場合はこのテキストに合わせて(?)Unicode-TOUになってるけど…OpenBSDの場合はGNU iconv使っているからやっぱGPLになるんですかねえ?
読み仮名の付与にkakasiを使う時しかこの変換は通らないので、mecab-neologdを使う場合への影響はないと思うけど。
多分これでucs2←→wchar16(sj3の内部コード)変換はできたはず。これだったら…以前作ったnwc2010-libkkcのUCS-2←→EUC-JP変換も古いテーブル(JIS0208.TXT)を使うんじゃなくlibiconvから生成したテーブルを使うようにした方が良いのかも。
もしかして、iconvのTRANSLATEオプションを使うとEUC-CN←→EUC-JPをそれっぽく変換してくれたりするんだろうか
…でもないか?記号類なんかは一応あるように見えなくもない。
むー、UCS-2の範囲だとSS3(3byte EUC)の対応はできないのか。

