kb10uy(@kb10uy@mstdn.maud.io)の投稿
kb10uy(@kb10uy@mstdn.maud.io)の投稿 📜もみあげと裾とコーディング
🔞性欲駆動アカウントにつき覚悟してください
Icon: 🐦️nunyu31
Header: 🐦️hataraku125
IIDX: 1751-5340
Switch: SW-4453-9803-7897
メカ夏稀もよろしくね: @mecha_natsuki


このアカウントは、notestockで公開設定になっていません。
Martian Moons eXplorer で MMX なんだ、そして Martian なんて形容詞が存在するのか

SPDXのライセンスを表現するための演算子には+というのがあって、もともとはGPLもGPL-2.0とGPL-2.0+という形で区別するようになっていたですが、FSFからの申し入れがあって現在の形になった
ジョブキューライブラリとかは Apache-2.0 のままにして本体だけ AGPL-3.0 にするという手もなくはないが
only と or-later があるの MIT とか Apache-2.0 にはなかったのでやや困惑したがまあ普通に考えて or-later でいいのか
-
-X

そういえば Base36 って雑に実装すると多倍長整数処理が必要そうに見えるんだけどなんかいい方法があるのかしら

このアカウントは、notestockで公開設定になっていません。
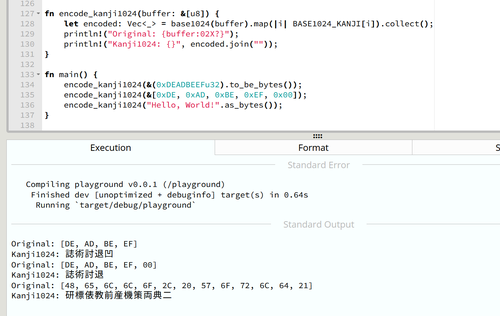
kanji1024_encode("日本語文字列を Kanji1024 でエンコードするとどうなる?")
=> 誠豆投眼現応境職府広着服推今航宗働参授丁羊賀立先肉治毎遊将正単就師単切幼治腹毎純将山令宗巣単弓明散寄毎畑将子効宗巣則保退凹
使う漢字をちょっとだけ変えてデコード処理も実装した
天上天下唯我独尊は 0F4260F406FBB40C3FAA だそうです
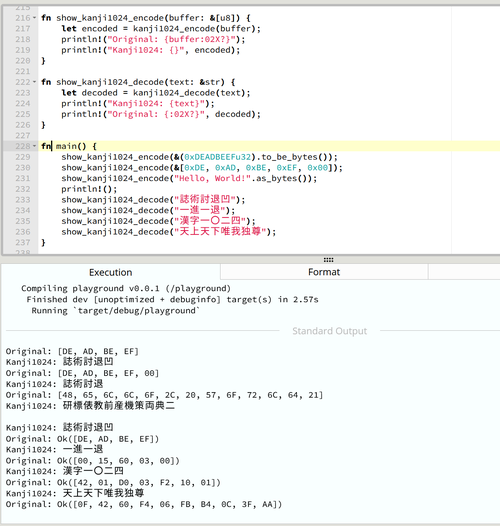
Base64 では発生してなかった問題として素朴にやると 8bit パディングが区別できないという問題が発生したのでマーカーとしてケツに凹を付けるという雑な実装をしています
小学校で習う漢字で足りない分の 18 字に「唯」を含めると 天上天下唯我独尊 になる 80 bit 数値が存在することになる
漢字 Base1024、熟語とかができるから案外日本人や日本語おたくにはウケがいい可能性がある
でも 2 割しか縮まない上に UTF-8 エンコードなら 3 倍、パーセントエンコードなら 9 倍なのであまりにも不利
hexstring から Base36 にしても 2 割強しか縮まないのは詐欺に遭った気分になるが、バイナリを Base64 にしても高々 4 割強しか伸びないのもなんだか不思議な気分になることがある
URL-safe かつ order preserved にするとなると - . 0~9 A~Z a~z かな
というより + / 0 1 ... A B ... a b ... という順列にするほうが簡単か
小文字より後ろにあるの { | } ~ だけなんだけど URL-safe じゃなくねえかこいつら
Base64 の場合ビットの詰め方を工夫しないとおかしくなりそうだな、頭に 16bit 入れて 144bit を 24 文字分としてエンコードするのが確実な気がする
log(16) / log(58) = 0.68...
log(16) / log(36) = 0.77...
なので Base58 から Base36 すると 1 割ちょい長くなるのか

case sensitive な ID 採番 いつか面倒なことになりそうだし base36 あたりまでで収めておいた方がいいんじゃないか?という気はする
1..9A..Za..z 、つまり Bitcoin アドレスと同じ仕様なら order-preserved になるのか?
> 前述したように、Base58は文字セット内の文字の並び順を実装に依存している。
お前!!
Base58 - Wikipedia
https://ja.wikipedia.org/wiki/Base58
(Flickr)Base58 がこれを満たすなら monaxia の ID の仕様は UUIDv7 の Base58 エンコーディングにしようかなあという思いがある
長さ順→辞書順というルール、結局 Base64 とかで時系列 ID をバイナリとしてエンコードする分には達成できる(∀x, y ∈ IDs, x ≧ y ⇒ Base64(x) ≧ Base64(y) は真なのか)?
投稿の ID を UUIDv4 で採番してること自体よりも Mastodon API 互換を謳っているのに採番ルールが準拠していないというのが問題なのか
シングルプレイなゲームで権利を買うタイプの DLC あんま見ないけどアセットのビルドとかローディング何も考えなくていいので 0.1 ARK ぐらいまでなら案外ありなんかな
途中抜けとは若干違うけど Trials Rising の RTA でもゴールテープ切ったらポーズメニューから抜けて良いみたいな規定があるので、比較的どうでもいいパートは厳密にクリアじゃなくても切り上げるみたいなのはそこそこあるっぽい