GAMEBOYの通信ポートってこんなことしてるのか http://mydocuments.g2.xrea.com/html/gb/comm.html
 SASANO Takayoshi(@uaa@social.mikutter.hachune.net)の投稿
SASANO Takayoshi(@uaa@social.mikutter.hachune.net)の投稿 OpenBSD(uaa@), Ham(JG1UAA), Ingress(Lv14, RES), Japanese(Sagamihara-city, Kanagawa)
Another side: https://social.tchncs.de/@uaa
npub1rarr265r9f9j6ewp960hcm7cvz9zskc7l2ykwul57e7xa60r8css7uf890
Messages from this Mastodon account can read via mostr.pub with npub1j3un8843rpuk4rvwnd7plaknf2lce58yl6qmpkqrwt3tr5k60vfqxmlq0w
GAMEBOYの通信ポートってこんなことしてるのか http://mydocuments.g2.xrea.com/html/gb/comm.html
とりあえず書類添付して変更申請の提出done。今年の1月4日に出して、4回目の補正後提出なんだけどw
そういう切り口から攻め込まれるとは流石に予想しなかったわ…
AmazonがFreeRTOS持ってるから、って地味にインパクトのある話だな…国内シェアがあるから、なんて某陣営はヌルいこと言ってる余裕なさそうだぞ?

このアカウントは、notestockで公開設定になっていません。
これは14MHz化して正解だったか。屋根裏アンテナなので空中線からの距離が取りにくいが50W以下の1.8mならどうにか取れてる。21MHzだと2.6mなので無理って話になるし。 https://www.tele.soumu.go.jp/j/others/amateur/confirmation/safety/
10W機にすれば万事解決なんだけど…無線機買い替える金も無いしIC-7200Mを売り払ったところで買い替えの資金にもならん。
おいおい…
□移動しないアマチュア局に対して、無線設備の設置場所の変更、電波の型式又は周波数の追加、空中線電力の増力、送信機の取替・増設・変更又は送信空中線の型式の追加を行う場合は、人が通常出入りする場所における電波の強度が基準値以下であることを確認した書類を添付してください。詳細については、『総務省 電波利用ホームページ』の「その他」→「アマチュア無線」から「電波の強度に対する安全施設について」をご確認ください。
そんな書類を付けろって言われてもだなあ…
ん-、sgemv_うんたらで計算する部分に関わるメモリは全てSVM化しないとダメなのかも。
っていうかさあ、いちいちメモリ→VRAMへコピーするってこと自体遅いに決まってるしー。VRAMだって所詮はRAMなんだしこの上にデータを直接置いちゃえば良くねって考えたくなるもんだ。
木綿も絹ごしも捨てがたいが…どちらか一つと聞かれたら木綿かのぅ
ああ、OpenBSDはdevelopersになりますね。ANNOUNCEMENTにOur developers areで記載があるので… https://ftp.jaist.ac.jp/pub/OpenBSD/7.3/ANNOUNCEMENT

このアカウントは、notestockで公開設定になっていません。
すみませんすみませんすみません…!
このアカウントは、notestockで公開設定になっていません。
OpenBSDはどうなんだろう(ぐぐってみたけど分からない)
このアカウントは、notestockで公開設定になっていません。
ああいう話を聞いてしまうと機材の買い替えとかGPUの購入とか早まった、とか思わなくもないのだけど…とはいえ今手に入れたから見える風景ってのもある訳で、その辺は授業料として割り切るしかないかなあ。
画像生成AIを始めたいけどグラボが高価で諦めている人に朗報、安価なAPUでも大容量なVRAMを割り当てて画像生成可能 (2023/8/18) https://gigazine.net/news/20230818-apu-gpu-vram-ai/ そらそーやろ、という話ではあるんだけど…メインメモリをCPU用/GPU用と分けるんじゃなく、必要に応じてGPUがCPUの扱ってるデータを気軽に触れるようになってれば良いのにと思ってしまうのはマズいんですかねえ(雑なドライバを作れば脆弱性の問題も引き起こしそうだし)。

でもあの時期に770LE/16GBを買った人達って本当に羨ましい
Phenom 9500→Phenom X4 9550のアレじゃないんだから…(ええ、わざわざ9500買いましたもん)

このアカウントは、notestockで公開設定になっていません。
@charsiuCat Intelへ問い合わせることをお勧めします。「本気で使ってるので」という熱意も届けられますし(本当かよ)
「ボードメーカーに聞いとくれ」「おっけ、聞いとくわ」で一旦closeした後にIntelからも問題が無いという一報が実は入っているので、感謝の言葉とともにその部分は再度確認してみましょう。
仮に、「Intel製のArc搭載カードに脆弱性」というのが本来の意図だったとした場合、「Intel Arc GPUに脆弱性」と報じた連中はIntelから訴えられても文句言えない気がする。影響範囲が全っ然違ってくるし、立派な営業妨害だよね…
ASRockからの返事は来ていて、「Intelから返答は受け取っている。ASRockのArc搭載カードには脆弱性は無い。心配せず使ってくれ。」ということなのでガシガシ使わせてもらうことにしますよ。
昨日更新したArcのドライバを見るに、ファームウェアのアップデートも同時に行われていたからおそらく何らかの脆弱性に対する対応を(Intelの製品なのでマイクロコードをちょろっといじった可能性もあるんじゃない?)したのではないかと見ているんだけども…
ボードの設計に問題があってファームウェア/マイクロコードの書き込みに難があるとか、うっかりES品のシリコン載せたボードをしゅっかしちゃったとか、そういう話だと対応変わるよね。真相は闇の中だろうけど。
Intel Arc GPUs Now Affected by New Vulnerabilities (12/Aug/2023) https://ts2.space/en/intel-arc-gpus-now-affected-by-new-vulnerabilities/ だと2022/Oct~2022/Decに出荷された「GPU」って書いてあるけど、脆弱性を指摘されているのがボードなのかGPUなのかで全然対応も問題も変わってくるよね。

INTEL-SA-00812 https://www.intel.com/content/www/us/en/security-center/advisory/intel-sa-00812.html を読み直して気になったんだけど、Intel® Arc™ Graphics Cards Advisoryであって、Intel® Arc™ Graphics AdvisoryとかIntel® Arc™ Graphics based Cards Advisoryではない点が引っかかってる。
ん-、
./opencl-c.h:16754:45: error: use of type '__read_only image2d_msaa_depth_t' requires cl_khr_gl_msaa_sharing extension to be enabled
float __purefn __ovld read_imagef(read_only image2d_msaa_depth_t image, int2 coord, int sample);
みたいなログを延々と吐かれても対処のしようがない訳で。
uaa@DESKTOP-251U0UF:~/dnetc-client-base/rc5-72/opencl$ ~/oclc/oclc.out -O-cl-std=CL1.1 rc5-1pipe.cl
16263
このアカウントは、notestockで公開設定になっていません。
あんだよ…PR出てるじゃん https://github.com/dcti/dnetc-client-base/pull/22

rc5-72/opencl/ocl_common.cpp b/rc5-72/opencl/ocl_common.cppにある、
/status = clBuildProgram(cont->program, 1, &cont->deviceID, "-cl-std=CL1.1", NULL, NULL);
この"-cl-std=CL1.1"を外すと動く。
ふーむ、ビルドはできるけどバイナリはerror -11で落ちるから…ここから追うことはできるのか。やるかどうかはともかく。
oclcで https://github.com/dcti/dnetc-client-base にある*.clをチェックした限りでは問題無いのに、dnetcのバイナリはerror -11になるのが解せないな。そもそもどういう形式で.clを格納してんの?って話になるのだろうけど。
結局linux-sunxiベース?boot0 blob使ったU-bootでやれってことですか… https://github.com/orangepi-xunlong/orangepi-build/commit/5b98978bd16bb3624e78a307d2067d461bfca417#diff-e0f333c6e19eccb7bda6f1f038d71ef8ae689d90752eef11b4f5da6e23af1c76

ネズミ入り込むと面倒だよね…(実家がそうだった)
怪談なのか、それとも(足音の規定が無いので)小動物の足音なのか…
このアカウントは、notestockで公開設定になっていません。
やっとASRockから返事来た「Intelに問い合わせ出してて、今チェックしてもらってる」って。
そういえばこういうmemset()は最適化で消えるんだっけ…?と思ったんだけど、関数の引数で取ってるsigに対するmemset()なのでこれは残さないとマズい。
https://github.com/bitcoin-core/secp256k1/blob/master/src/secp256k1.c#L374
関数内部で(ワークエリアとして)確保した領域に対するmemset()なら多分最適化で消されちゃうとなると…自分の書いたコードは果たして大丈夫なんだろうか…?あとで見とかないと。
とりあえずOpenCLでCPU→GPUないしGPU←CPU、GPU→GPUのデータ転送にかかる時間、雑な行列計算を行った際にかかる時間(CPUとGPUの比較)の測定をやってみたいなあ。どれくらいの規模のお仕事をさせると元が取れるのかが気になって気になって。
※何の生産性もないんだけど、興味には勝てぬ
と考えると、
{
char *buffer;
buffer = malloc(1024);
hogefuga(buffer);
free(buffer);
}
のhogefuga()が最適化によって消えないのは「たまたま消えてないだけ」という判断をした方が良いんだろうかね。まあ実際、関数の外には何も結果が出ていかないのだし。
コンパイラの解析機能が向上した日には、多分{malloc(); hogefuga(); free();}だけな処理も最適化で消される可能性はあるのかもしれないねえ…
現状だと、hogefuga()の後にあるfree()でbufferに対して何かするかもしれないからhogefuga()は消せない…仮にhogefuga(), free()を消したとしたらmalloc()も消さないといけなくなるけどそこまではまだ文脈を追えてないってところかねえ(malloc()~hogefuga()間にbufferに対する処理があった場合はどーすんのって問題もある)。
で、結局何をしようとしていたか思いっきり忘れてるので思い出そうとしてる。多分思い出せるけど面倒なのでやりたくない。
{
char buffer[1024];
hogefuga(buffer);
}
これだと最適化でhogefuga()の呼び出しが消えちゃって、
{
char *buffer;
buffer = malloc(1024);
hogefuga(buffer);
free(buffer);
}
これだとちゃんとhogefuga()が呼ばれる…多分malloc()とfree()の存在が抑止力になってるんだろう、なんとなく。

このアカウントは、notestockで公開設定になっていません。
駄目ですね…画質プリセット最高/高はハングアップすることあり、中でないと怖くて遊べません。
@reasonset 演算結果を格納した変数なりなんなりをprintf()なりすれば生き残るんですけどねえ…もうちょい考えてみます
計算するだけするけどその結果は使わない(時間測りたいので)、というコード…最適化かけちゃうと消えるという問題があって、どうやって残したものか頭を抱えてる。結果を無理やりにでも使うとかそういうことでもしないと残らないんだろうか。

チップを搭載したボードがたくさん出回っていることが「流れが来ている」ことにはならない
なあ?Core3566とかなあ?
なんかAllwinnerの時代は黄昏かなあ…Rockchipだよね、流れ的に

このアカウントは、notestockで公開設定になっていません。
今日更新したArc770のドライバで、果たしてオクトラⅡが安定して動くかというのは気になるところ。画質最高だと、何かの拍子にハングアップするんだよなあ…画質中(UHD730と同じ)だと大丈夫っぽいんだけど。
ちなみに画質最高だとオープニングはちょっとカクつくところがある。ウィンドウモード(1600×忘れた)という理由もあるのかも。
やっぱ770LE/16GBが投げ売りされていたあの時期に手にしておくのが正解だったんだろうなあ…ああいうチャンスを確実にモノに出来るかどうか、自分はできなかった身なのでその程度ってことなんだけど。
今回のドライバ更新でもその脆弱性に関してはどうなんのかという話は出てないし…
Intel謹製の750LE/770LEについてはIntelがきちっとサポートしてくれるだろうから心配不要なんだろうけど…ASRockのボード買った身としては例の脆弱性に当たるのか、(当たってなければそれで良しなんだけど当たってるかどうかの判定方法は示してほしい)当たった場合はどうすんのかをアナウンスしてくれないと困るんだよねえ。
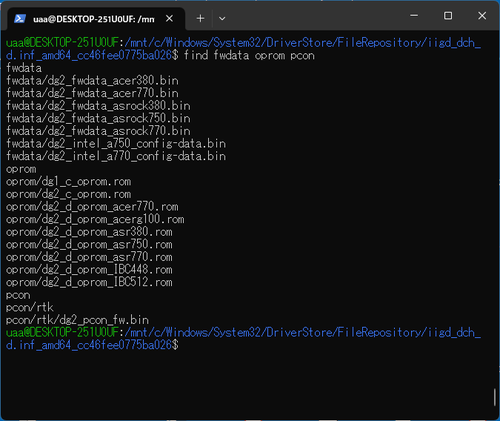
[2023/8/17--6:35:37:748] : Device: Fw Data Version: major_version-> 101-> oem_manuf_data_version-> 3-> major_vcn-> 1
[2023/8/17--6:35:37:749] : [fwdata_update]:FWData update Image written to SPI
[2023/8/17--6:35:37:749] : [GfxFwUpdateThread]: FWData Update Status:(1)
[2023/8/17--6:35:37:751] : [GfxFwUpdateThread]: FwData Reg Key Update completed successfully
なんて記述があるから…多分、ドライバと一緒に更新用のファームウェアも配られていて自動的に更新されてるんじゃないかなーと見てる。
ASRock Intel Arc A770 Phantom Gaming D 8GB OC、ファームウェアのアップデートが出てるけど…リリース日は2023/Jan/16。https://pg.asrock.com/Graphics-Card/Intel/Intel%20Arc%20A770%20Phantom%20Gaming%20D%208GB%20OC/index.jp.asp#FAQ
とはいえ、C:\Intel\FWUpdateService\IntelGFXFwUpdateToolLog_2023-8-17_6-34-45.logを見るに、(続く)
Downfall, VPGATHER(DQ他)命令による脆弱性ってことは…10世代以前のAVX非対応なCeleron/Pentiumは影響しないってことで良いのかなあ

freak31、「David Penn & Sex-O-Sonique - I Thought It Was You」が「David Penn & Sex O」(Oが曲名)になってる…名前の中に-が入るとちゃんとデコードできないのかな
Intel Arc A770のドライバの新しいのが来てるということで更新してみたけど、相変わらずdistributed.net[Windows:x86/OpenCL]はerror -11ですねえ…dnetc.exe内のOpenCLコードを抜いてビルドできるかどうか、元となるOpenCLソースをclBuildProgramに食わせるとどうなるか、辺りを調べてみる必要があるのかも。
WSL2/A770の方が異様に遅い…
uaa@DESKTOP-251U0UF:~/LPCNet/build.opencl/src$ time cat ~/test.out | ./lpcnet_dec -s > /dev/null
direct split VQ
dec: 3 pred: 0.00 num_stages: 4 mbest: 5 bits_per_frame: 52 frame: 30 ms bit_rate: 1733.33 bits/s
64 1 1 16 128 1152 160 160 160 160
ftest cols = 2002
real 146m16.882s
user 34m56.194s
sys 49m39.194s
uaa@DESKTOP-251U0UF:~/LPCNet/build.opencl/src$
OpenCL* 1.2 の活用: インテル® プロセッサー・グラフィックスでバッファーコピーを最小限に抑えてパフォーマンスを向上する方法 (2014/12/19) https://www.isus.jp/products/opencl/opencl-12-how-to-increase-performance-by-minimizing-buffer-copies/
同じコードをビルドしなおしても当然結果は変わんない…LinuxからHD630叩いてこの時間なんだけど、WSL2からA770叩いてる方はまだ処理が終わんない…
uaa@emeraude:~/LPCNet/build.opencl/src$ time cat ~/test.out | ./lpcnet_dec -s > /dev/null
direct split VQ
dec: 3 pred: 0.00 num_stages: 4 mbest: 5 bits_per_frame: 52 frame: 30 ms bit_rate: 1733.33 bits/s
64 1 1 16 128 1152 160 160 160 160
ftest cols = 2002
real 9m27.472s
user 5m46.797s
sys 4m29.678s
uaa@emeraude:~/LPCNet/build.opencl/src$
結果としては残念だけど、自分の手でデバイス動かしてる!って感じはあるので全然おっけーです。
LPCNet(OpenCL)、WSL2/Windows11上で動かしてみたけどあんましGPUが仕事してない感じ。でもこうやって動いてるのが可視化できるのは便利。
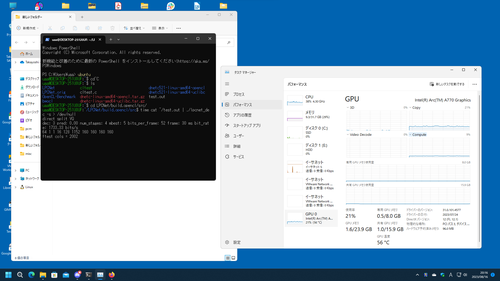
あー、ビルドし直しだこれ(無理やり-lOpenCL突っ込んでビルドしたからそれを再度やるのは面倒すぎる…CMake周りの整備しないとダメっすかそうですかマジやりたくない…)
AVX最適化入れて、i3-13100で4秒未満(i7-7700でも7秒切り)。
 の投稿
hayulf@misskey.design
の投稿
hayulf@misskey.design
このアカウントは、notestockで公開設定になっていません。
Pコア/Eコアの考え方って、ARMのbig.LITTLEだよねえぶっちゃけた話…ヘテロなコアなんて管理面倒じゃーんと思っていたのだけど、OSが頑張ってくれるおかげでその辺もどうにかなってるということなんだろうか。
でもイマドキのi3って一昔前のi7と同じ、4C8Tだし…(震え声
i7-13700KですらRTX4090を回しきれてないって、どんだけのCPU持ってくれば良いんですか…? https://pc-builds.com/ja/bottleneck-calculator/result/1jC1ci/1/general-tasks/1920x1080/
ボトルネック計算機…どの程度信用できるかは分からないけど https://pc-builds.com/ja/bottleneck-calculator/ i3-13100+RX6400だとグラボが弱い、RTX3060はちょうどよい塩梅という表示になってる。RTX3080だとプロセッサが弱い。
フレームバッファにBitBLTエンジンが付いてた程度の時代から、随分進歩しましたよねえ…
拡張性を犠牲にして性能爆上がり、という未来は見てみたいけど(けど、ってところにフクザツな感情がにじんでる)
x86でもオンチップメモリなCPUとか出てきてもおかしくなさそうだけど、PC/AT的にそれってどーなんという気がしなくもない。最終的には市場が決めるんだろうけど(M1/M2に限らず、Arm系SoCってオンチップメモリな物はまあまああるし…)。
そもそもASRockからまだ返事来てないし!
なんかArc A770の一件からGeForceに乗り換えよっかなとか考えてしまっていた部分があるけど、意外とグラボ入れない or A380辺りにスペックを下げてもいいのではって気になってきたな…確かに高速な計算機を手にするというロマンはあるんだけど。(時間はまだ少しあるのでのんびり考えます)
処理の内容がGPU向きなのでGPUに任せる(データも何もかもGPU側に預ける)という現状な訳だけど…CPUでもできるようになる、なら別にGPU要らなくね?って流れになるんじゃないかなーって。
あれかなー、NPUがCPUに内蔵って言われてるけど、性能次第ではStable Diffusionみたいな生成AIもCPUだけで(グラボ無しで)やれる時代もそんなに遠くなかったりするんだろうか。
iGPUもうまく活かせば計算機資源として活用できるのにね、とは思うんだけどなかなか難しいのが現実なんだろうなあ。i7-7700上でCPU版のdistributed.netとOpenCL版のを同時に動かすとちょっとスコアが(iGPU分だけ)上積みできるとか…って、GeForce/RADEON載せた方が全っ然速いじゃん、ではあるんだけど。
NPU内蔵CPUってAppleのBionic内蔵~とかあるから大分歴史があると思うんだけど、今後も増えてくんだろうなあ。

このアカウントは、notestockで公開設定になっていません。
GPU買うならOpenCLに触ってみるか…そういやLPCNet(ニューラルネットワークを使った音声CODEC)を以前AVX→SSE化したけどこれはGPUで速くなるんだろうか?という疑問があったので愚直にそれを実行してみたという訳です。
ここまで遅くなるとは、と逆に驚いちゃったけど…GPUに演算をさせる場合にどういうところが問題になるのか、というのは少しわかった気がする。
g: VRAM→メインメモリ p:メインメモリ→VRAMで見てみたけど、これは粒度が細かすぎて(転送コストが高すぎて)メインメモリ上でAVXに任せた方が速いに決まってる案件なのかも。
g 1024
g 128
g 1536
g 192
g 2048
g 3072
g 4608
g 512
g 64
p 1024
p 11348
p 1224
p 128
p 1536
p 157184
p 192
p 197120
p 2048
p 3072
p 3264
p 34816
p 416
p 4608
p 479232
p 512
p 576
p 594432
p 64
p 66048
p 98496
uaa@emeraude:~/LPCNet/build.opencl/src$ time cat ~/test.out | ./lpcnet_dec -s > /dev/null
direct split VQ
dec: 3 pred: 0.00 num_stages: 4 mbest: 5 bits_per_frame: 52 frame: 30 ms bit_rate: 1733.33 bits/s
64 1 1 16 128 1152 160 160 160 160
ftest cols = 2002
real 9m30.642s
user 5m33.714s
sys 4m47.241s
uaa@emeraude:~/LPCNet/build.opencl/src$
実装ミスってる可能性もある。
うーん、徒労に終わったか。CPUの方が遥かに速い。
OpenCL側のコードは実行時にコンパイルされるから、.clなファイルをエディタでいじる→a.out実行で反映という…なんというかスクリプト言語的な扱いで試せるのが驚き。
w += hint[i].w_offset + n;ではだめで、w += hint[i].w_offset + (n+2);では動くのは何故だ?
でもなんかOpenCL越しに何かが動いてる、ってことだけは確かっぽい。
ズレてる…?
sparse_sgemv_accum16..............: fail
0 0.000000 1.000000
1 1.000000 2.000000
2 2.000000 0.000000
3 3.000000 1.000000
4 4.000000 2.000000
5 5.000000 3.000000
6 6.000000 4.000000
7 7.000000 5.000000
8 8.000000 6.000000
9 9.000000 7.000000
10 10.000000 8.000000
11 11.000000 9.000000
12 12.000000 10.000000
13 13.000000 11.000000
14 14.000000 12.000000
15 15.000000 13.000000
16 80.000000 74.000000
17 83.000000 77.000000
18 86.000000 80.000000
19 89.000000 83.000000
20 92.000000 86.000000
ベクタエンジンの初期化を実行してなかったのでQueueの作成に失敗してた。sgemv_accum16は動いてるけどsparse_sgemv_accum16に失敗してるな
CL_INVALID_COMMAND_QUEUE(-36)ぅ?
計算結果については分からないけど、なんか動き出したことは分かった。テストコードに組み込んでみて、動くかどうかを確認しても良いかもな…
バッファへのポインタ、の配列なのか…なぜこんな作りになってる
A770→A380への移行は…一度A770を手にしてしまうとナシかなあ。手にしてなければアリなんだけど。
IntelのiGPU、お手軽に使うには必要十分だしこれで良くね?くらいの好印象は持ってたんだけどねえ(だからi3-13100と同じドライバで動かせるArcには結構期待してた)
このアカウントは、notestockで公開設定になっていません。
clCreateProgramWithSourceで何故Segment Faultが出るかなあ(多分ヘンな引数渡してるから)
安直に12GB載ってるRTX3060じゃダメなんだろうか…メモリ不足はボードを変える以外に補う手段がないし、結果が全く出せない(メモリさえあれば遅くても結果は出る)と考えちゃうんだけど。

このアカウントは、notestockで公開設定になっていません。
結局Arcの問題でもにゃってるのは
- どんな問題が潜んでるのか
- その問題は何をすると引き起こされるのか
- 回避方法はあるのか
- 特定の時期に出荷されたものはIntelへ問い合わせろとあるが3rd party製のボードに関してはどういう対応になるのか(これはボード製造メーカーに聞けとIntelは言っていた)
- 3rd partyメーカーの対応はどうなっているのか
これらが全然はっきりしてないということ。まあ公表してから対応するまで時間がかかるってのは分かるけど…もう少し情報を出してくれないと使い続けて良いのかどうかの判断すら難しい(というか諦めるしかないのかよ?って気分になってる)
うーん、Intel Arcの脆弱性の件、販売店(DOSPARA)側でも情報を把握できていない…そりゃそうだよなあ、あの発表で何を把握すんのって感じだし。
ASRockの対応にすべてが掛かってる。最悪の場合、Arc→Arcへの交換は諦めてGeForceの適当なのに変えることも考えないといけない。
とはいえ、GeForceに脆弱性がない、ということを誰が保証すんのかという問題もあるんだよな。
「ASRockのボードについてはASRockに聞いてくれ(要約)」というお返事いただきました。
そしてASRockからは、まだ返事が来ない。
(将棋界はうまくやってるというか、誰が上手くやったんだろう…最初はコンピュータ vs 人間にあれだけ否定的だったけど、人間が負けちゃってからうまくコンピュータを取り込んで評価値などの見せ方とかも工夫して、棋士のスキルアップにも活用してたりする。ああいうのが技術と人間の良い共存例だと思うんだけど。)
ちゃんとしたマネージメントのできる管理職がどれだけいるんだろう(結構悲観的な結論になるのでは)、というのが現実?
今の暮らしに安心がなければ明日への希望なんて生まれませんし、子供ファーストで今の労働者をないがしろにしているようではね…
「白紙の未来」https://www.ad-c.or.jp/campaign/self_all/self_all_01.html
これか。
このCM、確かにラジオで聞くけど…子どもの未来うんぬんよりも(親としてその発言はどうかというのはあるけど話が進まなくなるから一旦脇に置かせてね)、AIやロボットの普及により人間(労働者)を駆逐する連中にしっかり釘を刺すCMが必要なんじゃないの?って思った。必要なのはAIやロボットとの共存。

このアカウントは、notestockで公開設定になっていません。
(Xだとヘンなのに絡まれそうだからこっちでエアリプするけど)DQNの川流れ事件、証拠がない話まで出回ってるってツイートを見たけど…123便だけでは飽き足らず、こういう事件も陰謀論者の良いオモチャどころか歴史改変のネタとして消費されるんだろうか。
反応速いなIntel…回答は帰ってきてないけど、caseとして扱う旨の反応はあった。販売店とASRockからの反応は未だないけど…これは気長に待とう(向こうだってIntelに「これってどーゆうこと?」って聞いてるだろうし)

おたくが思うほど,「人間はミスをして当たり前」は浸透していないし,フェイルセーフも浸透していない
確か変換ケーブルでPS/2化できたはず
Baby-AT向けのキーボードコネクタかなあ、懐かしい
Intelのサポートリクエストにも念のため問い合わせ出してみたけど、どうかなー?
脆弱性の有無の確認方法、脆弱性があった場合の対応方法(ソフトの更新が要るならそのリリース時期及びパフォーマンスへの影響、ハードの交換があるならIntel以外のボードに関しても対応を受けられるのか、何も対応がないならどういう問題がどんな条件でどういう頻度で起こるのか)について、果たして回答が得られるかどうか…

https://mastodon.cardina1.red/@akahana@fla.red/110880468758186077
DRM つき電子書籍はサービス終了/オフライン環境/未対応デバイス等でアクセス不可能になるので Sustainable Documentation Goals を達成できない (適当)
「紙の本!SDGsに反するのでひっ捕えろ!燃やせ!」なんて、「ほほぅ、紙の本とはまた贅沢な…」よりもさらに深刻な事態じゃないですか…

このアカウントは、notestockで公開設定になっていません。
そこはお金出さないといけない領域だと思う。ていうか、どの領域もお金も出さず、むしろ人も減らしたい(その割には能力高い人が欲しい)なんて言ってるようじゃ…
このアカウントは、notestockで公開設定になっていません。
あれ、今度はclinfo通ってる。
int test(void)
{
asm __volatile__(".word 0x144f0000");
asm __volatile__("b 0x13c0000");
asm __volatile__(".word 0xd503201f");
asm __volatile__("nop");
asm __volatile__(".word 0xd65f03c0");
asm __volatile__("ret");
}
消す前にメモとして投げちゃう
一応販売店には(電源の動作報告と対応のお礼も併せて)何かあったら教えてくださいって問い合わせ出して、ASRockにもどうしたもんかねって問い合わせ出してみたけどさ。てーかCPUはマイクロコードの変更で対応したみたいだけど、GPUはどうすんのかなあ。なんとなく、脆弱性あるけどこのまま頑張ってね(はぁと)と放置な悪寒が。
https://jvn.jp/vu/JVNVU99796803/ これさ、「開発者にお問い合わせください」ってなってるけどIntelの文書 https://www.intel.com/content/www/us/en/security-center/advisory/intel-sa-00812.html では「Contact Intel product support in your region」なんだよね。とはいえ自分の持ってるのってIntel謹製のLimited EditionじゃなくASRockのなんだけど…それでもIntelへ問い合わせて良いんだろうか?
歳食ったせいというのもあるかもしれないけど、PS1~PS2時代のいかにもポリゴンっぽさ丸出しな感じのゲームで良いじゃねーかと思うことが増えてる気がする。

このアカウントは、notestockで公開設定になっていません。
sparse/非sparseはやっぱ分ける。めんどいので。
てーか本当にこの2年間は入手するモノに何かしらの不具合があるケースが多い気がする。無駄な時間を使いたくないなら本当に「定番品」を適切なお金、それこそ保険とかサポートとかの代金込みで払うくらいのことをしないとやってらんない気がする。
脆弱性報告の対象品を手にしている、という実績も解除できましたし♪(泣きながら
Arc A770でオクトラⅡ(画質設定最高/FullHD)動かしてるとハングアップすることが二度あったんですが…WSL2(Ubuntu)のclinfoが「Abort was called at 62 line in file: ./shared/source/os_interface/os_interface.h」とエラー吐いて動かないんですが…それでもまあ思い切って買ってしまったことは後悔してないです多分。
「見たら買え」(秋葉原の鉄則)
確かにそれはありますね。自分も何度か悔しい思いを…。

このアカウントは、notestockで公開設定になっていません。
[Spoilers] [LONG] I tried translating the Latin lyrics again, and this is what I got. https://www.reddit.com/r/octopathtraveler/comments/jr5v59/spoilers_long_i_tried_translating_the_latin/ 歌詞を聞き取るためにPCMエディタとFFTフィルタを使うって…イマドキはそれくらい普通にやるんですかね(驚
rowsとcolsの値が要るけどsparse系はcolsについては不定になってるので最大値を調べないといけないという厄介な問題がある気がする…って、テーブル構築しながら調べれば良いから問題はな…あるね。最大値分からんし。
とりあえず最初のうちはsparse_うんたら系の実装(非sparseに関してはsparseの特殊形として扱う)で、高速化が見込めるかどうかを見てみるか。脈が無ければさくっと捨てれば良い。
ん-、(rows / step) * (cols + 1)が最大かなあ。
for (i=0;i<rows;i++) out[i] *= SCALE;
for (i=0;i<cols;i++) x[i] = (int)floor(.5+127*_x[i]);
idxのサイズも事前計算(というか一旦テーブルを舐める必要あり)
idx参照用のリストも作成するからサイズは分かる
問題はwのサイズだよなあ。32(もしくは16)×rows×colsかなあ。

おたくが沸いてから普及するまでには時間がかかるのだなぁ そして最初に湧いていたおたくのいくらかは既に飽きて別のことで湧いている
(CPUがブン回っているので)暑い
OpenCLいじる前に、DOT_PROD非対応なvec_sse.hのメンテしろって感じっすね
sparse_うんたら系もアレかなあ、CPUがGPUの処理しやすい形に編集してから渡せばいいのかなあ(なのでカーネル毎のワークロードが偏る可能性あり)。
※今までそれが実現されていないということは、単に手を付けていないだけなのか、手を付けても現実的ではない(不可能である)ことが示されているかの、どちらか。
Tutorial: OpenCL SGEMM tuning for Kepler https://cnugteren.github.io/tutorial/pages/page2.html
この例にもあるように、C[n * M + m] = acc;すべて独立した要素に対する独立した処理を並列化しているので、C[n * M + m] += accみたいな依存性のある処理については考えないといけない。
data[x] += foobar、真面目に書くとdata[x] = data[x] + foobarになる訳だし、こーゆう処理を複数のカーネルに分けちゃうと「別のカーネルが読み取るグローバルメモリーへの書き込みを避けます」に違反しちゃう。 https://hpc-event.jp/hpsc2023/material/hpsc2023_day3_workshop_part2.pdf
ていうか、OpenCLのカーネルプログラミングって複数のカーネルから同じメモリアドレスに関して同時に読み書きが発生した場合って何が起こるんだろう。ちゃんとロックがかかるとは考えにくいんだけど…
JVNVU#99796803 Intel製品に複数の脆弱性(2023年8月)
「2022年10月から2022年12月までに販売された次の製品に関するサポートについては、開発者にお問い合わせください。
INTEL-SA-00812: Intel Arc graphics cards A770およびA750」
https://jvn.jp/vu/JVNVU99796803/
どうやら「当たり」を引いちゃったみたい。