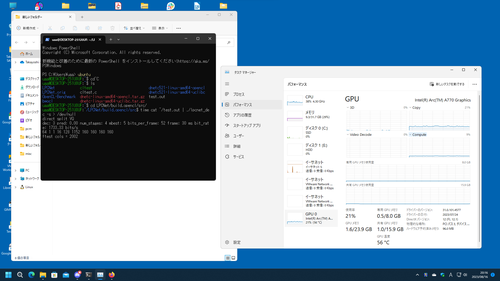
WSL2/A770の方が異様に遅い…
uaa@DESKTOP-251U0UF:~/LPCNet/build.opencl/src$ time cat ~/test.out | ./lpcnet_dec -s > /dev/null
direct split VQ
dec: 3 pred: 0.00 num_stages: 4 mbest: 5 bits_per_frame: 52 frame: 30 ms bit_rate: 1733.33 bits/s
64 1 1 16 128 1152 160 160 160 160
ftest cols = 2002
real 146m16.882s
user 34m56.194s
sys 49m39.194s
uaa@DESKTOP-251U0UF:~/LPCNet/build.opencl/src$