オクトラⅡ、画質最高で時々ハングする問題が解決したかどうか試さないといかんのかな…
 SASANO Takayoshi(@uaa@social.mikutter.hachune.net)の投稿
SASANO Takayoshi(@uaa@social.mikutter.hachune.net)の投稿 OpenBSD(uaa@), Ham(JG1UAA), Ingress(Lv14, RES), Japanese(Sagamihara-city, Kanagawa)
Another side: https://social.tchncs.de/@uaa
npub1rarr265r9f9j6ewp960hcm7cvz9zskc7l2ykwul57e7xa60r8css7uf890
Messages from this Mastodon account can read via mostr.pub with npub1j3un8843rpuk4rvwnd7plaknf2lce58yl6qmpkqrwt3tr5k60vfqxmlq0w
オクトラⅡ、画質最高で時々ハングする問題が解決したかどうか試さないといかんのかな…
Arcのドライバ、8/23リリースの31.0.101.4669に更新したけどdistribued.net clientの(cl-std=1.1非対応)問題は解決してないっすね。バイナリパッチをdnetc.exeに当てろってことで良いんですかね…
とりあえず自分のコーディングスタイルを見直すきっかけにはなった。一応style(9)準拠にしてるのでそれを継続ってことで。
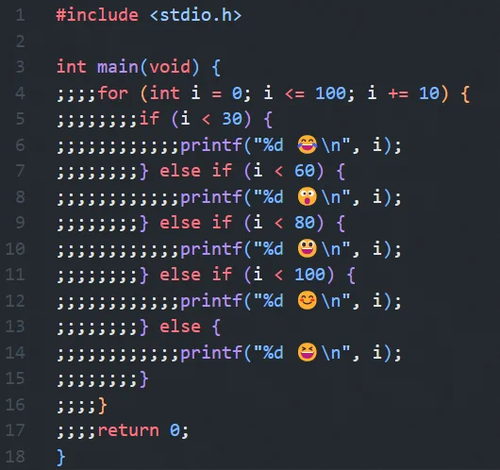
;でインデント、面白いアイデアだとは思うけど…
for (i = 0; i < 200; i++)
do_something();
みたいなケースへの対応は難しいんじゃないかなあ。
まあコーディングスタイルを新しく作ってるようなもんだから、たとえfor()だのifだのに続く処理が一行しか無くても必ず{}で括れというスタイルを強制した上で;でインデントしろよなー、ということなんだろうけど。

乗るしかない、このビッグウェーブに
[Xユーザーのふもさん: 「え、まだタブやスペースでインデントしてるの?時代遅れじゃない? 今どきはセミコロンだよ。 https://t.co/YMEFTwyXI2」 / X]( https://twitter.com/fumokmm/status/1697088065829994753 )
tiger lake(11th Gen)以降のCeleron/PentiumはAVX2対応持ってるので、一生懸命SSE対応したところで意味無いんだよね実は。
LPCNet、本家はxiphのなんだけど…FreeDV2020向けのdrowe67版をここしばらく触っていて、本家からかなり乖離しちゃってるから少しメンテしないといけないのかもね(SSE周りとか)というのがあらすじ。
8x4(sparse_sgemv_accum8x4)対応は取り込めないかなーと思ってみてみたけど、これはかなり影響範囲が大きそうなのでやめた方が良いのかも https://github.com/xiph/LPCNet/commit/4a39b4131a0ea28208831e179b0f1d10470b449b
なので、結局は
- vec_sse.hは廃止
- vec_avx.hをそこそこ新しくする
- SSEの時もvec_avx.hを使うようにお願いする
という対応が今できる最善ってことになるか。vec.hの挿げ替えもちょっと危ないかな。

パンを食った枚数をいちいち覚えちゃいないのと同様、投げたPRなんていちいち覚えちゃいないよ。
…ってこんなこと書いてると「ロクにテストもせず何やってんの」と言われそうだなあ。あん時何やってたんだっけ自分というのを振り返ってるだけなんだが…
あと、これも検証。defined(__AVX__)であればvec_avx.hを通すことでAVX化は可能、defined(__SSE__)が無い場合はvec_avx.hも通さないしSSE化もしない(それ以前にビルドエラーで止まる)。
なので、defined(__SSE__)でなんかする、でSSE対応してたという過去の話についてもまあ(やってることが怪しいとはいえ)多少の意味はあったということか。
一応供養のために動作テストをしてみたけども…
- vec_sse.hの結果はベクタ命令使わない場合と同じ(vec_avx.hの結果は少し異なる)
- 当然だけどvec_avx.h使えばSSE/AVX同じ結果になる
- vec_sse.hだと16.6sec, vec_avx.hでSSE化すると8.8sec(AVXと遜色ない結果になる)
やっぱ廃止で正解かな?出力結果は間違いじゃなかったみたいだけど。
自分で言うのもなんだけど、vec_sse.hなんてクソ(を放り込んだのは自分)を放り込む前に、何故vec_avx.hがSSE対応してるかを見抜けなかったのかと当時の自分に説教したい…という訳で、きちんと尻を拭おうと思います。ごめんなさい。 https://github.com/drowe67/LPCNet/pull/60


このアカウントは、notestockで公開設定になっていません。
Nonchalant(Radio Edit)/Dack Sauce…Radio Editじゃないの( https://www.youtube.com/watch?v=xDbvqXmY-uk )を聞くことが多いけど、Radio Editも良いっすね。

@reasonset どうも自分の引いたblog記事が引用していた文献が古かったのでradeontopを紹介しちゃった感じですね…(確かに今はradeonドライバではなくamdgpuドライバなので)
Monitoring AMD, Intel and NVIDIA graphics card usage under Linux https://rk.edu.pl/en/monitoring-amd-intel-and-nvidia-graphics-card-usage-under-linux/ (12/May/2014)

リスキリングとかいうのって、リストラと同じく、首切りの言い換え語という理解をしている

このアカウントは、notestockで公開設定になっていません。
おおおおおお
uaa@DESKTOP-251U0UF:~/LPCNet/build.opencl/src$ time cat ~/test.out | ./lpcnet_de
c -s > /dev/null
direct split VQ
dec: 3 pred: 0.00 num_stages: 4 mbest: 5 bits_per_frame: 52 frame: 30 ms bit_rate: 1733.33 bits/s
64 1 1 16 128 1152 160 160 160 160
ftest cols = 2002
real 44m18.963s
user 21m12.529s
sys 20m38.585s
uaa@DESKTOP-251U0UF:~/LPCNet/build.opencl/src$
Windows上のタスクマネージャで見るにSVM化前→後を比較すると
Copy 21%→92%
Compute 9%→63%ということで、前よりはArcが仕事をしてくれるようにはなったんだと思う。とはいえCPU単体よりはるかにおっそいし、HD630よりも遅い結果になりそう(HD630ならもう終わっている時間)。LinuxでもCPUの仕事っぷりはtopで見られるとして、GPUに対する同様なツールを探してみる必要があるのかなあ…って良いもんあるじゃないですか
Linux で GPU 負荷を調べる https://dskjal.com/linux/check-gpu-load.html
あとはこれをArc上で動かせばいいのだけど…さて、何時間かかるのやら。
最後に落ちる問題を解決+ちょっといじっても、変わらない(Linux/HD630)。
uaa@emeraude:~/LPCNet/build.opencl/src$ time cat ~/test.out | ./lpcnet_dec -s > /dev/null
direct split VQ
dec: 3 pred: 0.00 num_stages: 4 mbest: 5 bits_per_frame: 52 frame: 30 ms bit_rate: 1733.33 bits/s
64 1 1 16 128 1152 160 160 160 160
ftest cols = 2002
real 24m8.163s
user 12m36.059s
sys 12m26.866s
uaa@emeraude:~/LPCNet/build.opencl/src$
CPUじゃないデバイスをいじって計算させるって面白いなということでしばらく遊んでみたけど…性能を出すには本当に難しい。CS学んでアルゴリズムとかデータ構造とかちゃんと分かってないと扱えないというのは言い過ぎかもしれないけど、なんかそんな気がする。
多分SSE/AVX/NEONで書いたところだけOpenCLで書き直すというやり方じゃ全然だめで、もう少し大きい単位…ロジック丸ごとをOpenCL化するとかしないと速度出ないはず。データもCPU/GPUのどっちに寄せるかとかも考えないといけないし(極端な話入力と結果だけCPU、他全部GPUとかそうでもしないと)。あとは処理の粒度であまりにも細かいとやっぱりCPUの方が融通利くし速いとか、そういうのもありそう。でもどれくらいの大きさにしないと利点感じないのかなというのはある。RC5-72 crackingみたいに軽い(?)データでも計算数が多いのはGPU有利って話もあるし。
OpenCL全っ然分からない…なにこの難しいの…使えば速くなるっていったじゃん(いってない)
面倒だから分けたままにしちゃう
ほんとに速度変わんない…24分かかってる(おい…)
ん-む、重み付け用の定数を別のSVMにマップしてそっちはmap/unmap対象から外したけど速度への寄与はなさそうだな…面倒だから以前と同じくワークバッファと一絡げにしちまおうか
我ながらくっだらないことに時間使ってるなーとは思うが…
lpcnet_createでvector_buffer_allloc()してるけどこれに対してfree()するのはさすがに問題。ベクタエンジン使わない場合はcalloc()/free()で、使う場合はvector_buffer_alloc()/vector_buffer_free()のペアにしないといけない。直したところで、CPUより遅いって結論である以上ぶん投げてもいいんだけど…一応Arcでもどの程度遅いのかは見てみたい(わくわく)なので。
とりあえず明日以降の作業だな。
ってことはSVM化でマジ遅くなったのかよ…
(gdb) backtrace
#0 0x00007f05fa9d8d4a in __GI___libc_free (mem=0x7f05e2689000)
at ./malloc/malloc.c:3362
#1 0x00007f05fac0a228 in lpcnet_destroy ()
from /home/uaa/LPCNet/build.opencl/src/liblpcnetfreedv.so.0.5
#2 0x00007f05fac0aa07 in lpcnet_freedv_destroy ()
from /home/uaa/LPCNet/build.opencl/src/liblpcnetfreedv.so.0.5
#3 0x00005586b00779d1 in main ()
(gdb)
ふーむ…?多分mallocしてないものをfreeしようとしたとかそんな感じの話か。んでもってlpcnet_destroy()呼んでるってことは一応最後までは走ってる(最後の最後でコケると)。
(ぷるぷる震えています、あまりにもあまりなので)
あ゛ー、core吐かせる設定せずにジョブ動かしてsegvしたからでばっぐできないあああああああああああ30分近くまたやり直しああああああ><dfjklgfs;djklgs
氷河期世代とっ捕まえて「お仕事があるだけ感謝しな、あ?」というのがイマドキのスタンダードなんでしょう?(と敢えて煽り気味に
でもさ、採用側って履歴書見て「このスペックでは…」って考えてるじゃん。フツーにさ。
他人にスペックという言葉を使っている人をみてゾッとした (2023/8/29) https://www.orangeitems.com/entry/2023/08/29/000000

メモリリークは潰したと思ったんだが…まだ居たのかな
SVM化(Coarse)してみたのをLinux/HD630で動かしてみたけど、昔ながらのEnqueue{Write,Read}Bufferした方が速いってどういうことよ…(しかも落ちてるw)
dev/null
direct split VQ
dec: 3 pred: 0.00 num_stages: 4 mbest: 5 bits_per_frame: 52 frame: 30 ms bit_rate: 1733.33 bits/s
64 1 1 16 128 1152 160 160 160 160
ftest cols = 2002
Segmentation fault
real 24m7.599s
user 12m32.813s
sys 12m26.253s
uaa@emeraude:~/LPCNet/build.opencl/src$
音声処理程度ならもはやCPUで十分に賄える、より処理速度を必要とする重い仕事でないとGPUを活かせない…ということなんだろうなあ。
そして当然ながら速度は全然出ていない。CPUにやらせた方が遥かにマシなレベル。
うーん、必要なデータをVRAM上に置くようにしたら動き出したけど…メモリリークが酷い…どっかで借りたものは返していないところがあるのかも。
あんまし一般的じゃないんだろうが、extern float foobar[256];みたいにサイズを明示するしかないかなあ。
メルカリでの相場は知らないんだけど、どうなんだろ(ヤフオクよりこっちの方が古本買うのに便利な時があるような)
ビギナートランジスタ読本などの、奥澤清吉先生の本…最近はオークションでも出物は少ないし値段も上がってる感じ。

このアカウントは、notestockで公開設定になっていません。
fdata-sectionsでデータをセクション分けして(そのサイズも取れる?)、それをVideo-RAMへ転送するコードを書けばいいんだろうか…なんかROM化コードと同じようなことをやろうとしているような気がしなくもなく。
(伏せる)一択じゃん…(他を知らないので)
このアカウントは、notestockで公開設定になっていません。
@1f46356a832a4b2d65c12e9f7c6fd8608a285b1efa896773f4f67c6ee9e33e21 なんかこの辺のバッファの内容もGPU側から触れるように細工しないとダメっぽい

このアカウントは、notestockで公開設定になっていません。
uaa@emeraude:~/LPCNet$ grep static build.opencl/_deps/lpcnet-src/nnet_data.c
static float gru_a_embed_sig_weights[294912] = {
static float gru_a_embed_pred_weights[294912] = {
static float gru_a_embed_exc_weights[294912] = {
static float gru_a_dense_feature_weights[147456] = {
(省略)
uaa@emeraude:~/LPCNet$
なんか知らんソースを自動生成して食わせてんのかよ…💢
うーん、思いつくところは書き換えたんだけど、どうもSVMとして確保したメモリではないポインタを食わせようとしている箇所があるようで、「そんなアドレスは知らぬわ」と蹴られるんだよなあ
nnet.cおよびlpcnet.cの、該当するコードの該当する関数が使うバッファを、ベクタエンジン用のバッファに挿げ替えるという面倒な作業があるけど…手間がかかるだけで(再帰とかstaticとか使ってなさそうだと)厳しいものではないと思う多分きっとおそらく。
そこまで手をかけても、実はAVXの方が早いのでした残念、という結果になる可能性は高いと思うよ?
test_vecのSVM対応は終わった。ここから本番…nnet他全て必要なものを、SVM対応しないといけない(面倒臭い)。