This account is not set to public on notestock.
 らりお・ザ・何らかの🈗然㊌ソムリエ(@lo48576@mastodon.cardina1.red)님의 게시물
らりお・ザ・何らかの🈗然㊌ソムリエ(@lo48576@mastodon.cardina1.red)님의 게시물

This account is not set to public on notestock.

This account is not set to public on notestock.
なーにがフランス書院じゃ、大日本帝国書房を立ち上げろ (???)
This account is not set to public on notestock.

This account is not set to public on notestock.
スラッドシュッシュジェーピーのコメント基本的に読む価値ないでしょ
abstract
https://tdg.docbook.org/tdg/5.2/abstract.html
info element としての abstract 要素が近い役割を持ってるか。
でもこれは本文に明示的に含まれるかはっきりしないのでやはり本文の一部として使いたい場合は微妙。 #docbook
> Processing expectations
>
> Formatted as a displayed block. Sometimes suppressed. Often presented in alternate outputs.

This account is not set to public on notestock.

【Fediverseの話題】
Twitter CEOのジャック・ドーシーがこんなことを申しておりまして。
<引用>
https://www.theverge.com/2019/12/11/21010856/twitter-jack-dorsey-bluesky-decentralized-social-network-research-moderation
Twitterは小規模な研究者チームに資金を提供して、「ソーシャルメディアのオープンで分散型の標準」を構築し、Twitterをその標準のクライアントにすることを目標としています。</引用>
https://twitter.com/jack/status/1204766078468911106
起点になっているドーシー本人の投稿はこれかな。
https://twitter.com/bluesky
プロジェクトはBlueskyというそうです。
もちろんMastodon界隈でも話題になっております。興味のある人は観測し始めるといいですよ。 #fediverse #distsns #twitter #bluesky

ところでこういう『特定の事象への関心が表出しやすいタイミング』で、ハッシュタグと関連キーワードの購読設定[1]をして、その中から興味深い発言をしている人をどんどんフォローしていくことで、関心を軸とした情報収拾が捗るアカウントが作れるんじゃないかと思います。
そういうFediverseの使い方をする人、まだあまり見ないので、もう少し増えていくといいなぁ、と思ってます。
[1] #fedibird の独自機能

This account is not set to public on notestock.

This account is not set to public on notestock.

This account is not set to public on notestock.

This account is not set to public on notestock.
つまり「動作自体は分散型だけど使用策定は twitter がオレオレでできるようなプロトコルを広めて、 SNS を思うように操りたい」という話でしょ
ActivityPub のようなオープン標準は一社で独占的に使用を弄れないのでさぞご不満なのでしょうね、開発者を無視して独善的なサービス改悪を繰り返してきた某社としては
TwitterのCEOが「分散型ソーシャルメディアのオープン標準」の開発推進を発表 - GIGAZINE
https://gigazine.net/news/20191212-twitter-open-decentralized-standard/

 님의 게시물
herschel@raptol.net
님의 게시물
herschel@raptol.net
This account is not set to public on notestock.
でもよく読んだら「オープン標準を開発するために」とか言ってんな、笑ってしまった
誰が追従したがるのかな
W3C と某社だったら、皮肉でもなんでもなく普通に W3C の方を選びません?

This account is not set to public on notestock.
どちらかというと運営者のモデレーション負荷を分散させたいみたいなアレが読み取れるし、フランチャイズ twitter サーバでも立てられるようにしたいのか?

This account is not set to public on notestock.
そもそも blockchain がどう差別化になるのかよくわかってない顔をしている
改竄検知とかは基本的に署名で事足りるじゃんね。それこそ個々のクライアントがサーバにでもならない限りは
サーバ間で時系列について一貫性のあるデータを共有したいとか? でもそれは Matrix でできるような
スマートコントラクトみたいなのを使って、たとえば発信者サーバですら発信日時を弄れないような仕掛けを……とかであれば面白そうだけど

This account is not set to public on notestock.
WHATWG はもっと HTML 周辺ピンポイントな組織なので標準化に必要なわけではないし、それを言ったらそもそも W3C にやらせなくてもオープン標準は名乗れるので
Matrix もオープン標準名乗ってなかったっけ

This account is not set to public on notestock.
This account is not set to public on notestock.
まあ「人々からの意見は広く募りますよ」と言いつつ Twitter 社がイニシアチブあるいは最終決定権を握る、みたいな感じのことがしたいのでは。
This account is not set to public on notestock.
ブヨックチェーン、べつにサーバ間のために使うこともできるので必ずしもクライアント間 P2P を含意しないものと考えている
まあここで何を言っても一年後の天気を当てようとするようなものやな
日本に再び「化石賞」小泉環境相の演説受け 国際NGO | NHKニュース
https://www3.nhk.or.jp/news/html/20191212/k10012211821000.html
> 「COP25」での小泉環境大臣の演説を受けて、国際NGOのグループは温暖化対策に消極的な国に贈る「化石賞」に再び日本を選びました。
> 小泉大臣は「驚きはない。受賞理由を聞いて私が演説で発信した効果だと思った。的確に国際社会に発信できていると思う」と話していました。

This account is not set to public on notestock.
My net work... とか My net gear... とか脳裏を過った

brastel の My 050 なのですが、コールセンター(おそらく向こうもIP電話)の待ち受け音楽が超高音質という効果がありますが、まれに音が途切れるのが 050 番号クオリティだなと。。。
無料マンガサイト「マンガクロス」で「上伊那ぼたん、酔へる姿は百合の花」が読めるよ! https://mangacross.jp/comics/kamiinabotan #上伊那ぼたん #マンガクロス
これ良いな、そのうち買おう


This account is not set to public on notestock.
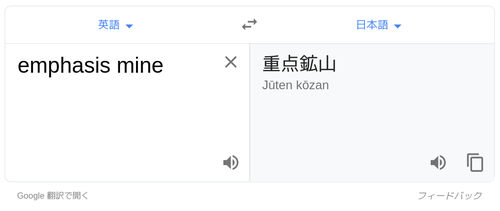
emphasis mine の意味を知りたかったわけじゃなくて、「emphasis mine のような註記そのものを英語で何と呼ぶか」が知りたかったんだけど

学術情報XML推進協議会(XSPA)なんていうものがあるのか
JEPA|日本電子出版協会 2020年1月15日 学術出版デジタル化最前線-世界の趨勢と日本の危機- https://www.jepa.or.jp/seminar/20200115/

XML,ちゃんと学びたいが何から手をつけるべきか何もわからんマンのまま月日だけが経過している.定番の教科書的なものはあるんだろうか.
O'Reilly Japan - 入門 XML 第2版
https://www.oreilly.co.jp/books/4873111846/
これとかは若干古いけどいい感じの入門でしたね #XML

XML は文法自体は (処理系を作ろうとしなければ) それなりに簡単なので、雰囲気でやっていてもそれなりにわかります (ただし処理系はムズい)

マッチョの発言すると W3C の資料みたくなってしまうけどそうじゃない入門書とかよくしらないなー。SOAP とか COORBA とか流行ってた 20 年前ならともかく現代に XML の本とか出てるのかな。
文書形式としての XML を知りたけれれば、入門としてのおすすめは DocBook と XHTML あたりですね。
あと TEI というのもあるけどこれはめちゃくちゃ複雑。複雑なんだけど、現実の文献の情報を損なわずにエンコードできるのでたぶん界隈ではよく使われている。
DITA というのもあるけど、これはマニュアルとか説明書とかそっち方面に向いているもの? これは処理系拡張を作ることを視野に入れて設計されている (モデルとして継承みたいなものを使っている) おもしろい形式だけど、やっぱり多少複雑
DocBook 5.2: The Definitive Guide
https://tdg.docbook.org/tdg/5.2/index.html
DocBook は現時点のリリースが 5.2 でのサイトが公式。リファレンスもある。
DocBook は技術文書・書籍向きなんだけど、コマンドのマニュアル (man page) とかの生成に使われていたり、 AsciiDoc という軽量マークアップ言語のスキーマのベースとして使われていたりするので、 IT 系では割と普及している方だと思う #docbook #asciidoc
TEI: Text Encoding Initiative
https://tei-c.org/
TEI ガイドラインP5 目次
https://docsci.infon.org/stack/P5JA/index-toc.html
TEI (Text Encoding Initiative) は本当にクソデカ仕様なので、たぶん人文科学系の用途では実用上はこれをおすすめすべきなんでしょうけど、入門にはとことん向いてないと思います。
TEI の概念とかその辺りの触りを紹介するサイトとかを適当に探すくらいで良いかと

DITA Open Toolkit
https://www.dita-ot.org/
Darwin Information Typing Architecture - Wikipedia
https://ja.wikipedia.org/wiki/Darwin_Information_Typing_Architecture
DITA は…… まあ概念は面白いと思うけどこれも入門には向いてないと思います。
あと、これは最初から電子化されたものを書くなら良いだろうけど、既存のレガシーな文書を持ってくるのはちょっと手間かもしれない


This account is not set to public on notestock.
XML 自体はタグでマークアップするだけだから 3 秒で把握できそうだけど xslt とか xpath とか周辺技術や特定の DTD とか XML のテンプレートとか読み解くとかそういうのがね?わからなくなりがち
XML 処理のための技術だと、 API としては SAX / StAX (ストリーミングパーサ) と DOM (木構造データ) あたりの話があるけど、これはプログラム書いたりガッツリフィルタする人向けなのでひとまずスルーしていいか
より通常のソリューションとしては XSLT (XML の木構造に対して、パターンマッチによって木を組み替えたりテキストを吐いたりなどできるテンプレート言語) や、 XPath (XML の木構造に対して、テキストにおける正規表現のように条件やパターンを記述できるクエリ言語) がある
ちなみに XSLT 3.1 とか XPath 3.1 が出ているけど、対応しているフリーの処理系はほとんどないのでパンピーとしては XSLT 1.0 と XPath 1.0 を使うことになります。
あと XQuery という XPath を拡張したようなクエリ言語もあって、これは XML データベースとかに使うと便利みたいな話。
なんだけど、残念ながらこれもたぶんオープンソースな処理系があるかわからないし下々の民に普及しているようには見えない
XPath は XML の基本概念 (名前空間、ノード、属性など) がわかっていれば割と簡単に納得できると思う。 CSS でセレクタの概念について事前知識があるとなおわかりやすいかと。
XSLT も表面的には素朴なんだけど、若干癖があるので本格的に使いこなすには若干の修練がいるかも。まあ汚くなっていいなら基本的にやりたいことできるので軽率に使ってみてもなんとか役立つ類の技術だと思う
TEIの策定とかはやっぱり欧米が中心なので,西洋の主要な文献はすでにそれなりの形式でデジタル化済みであったりして,ヨーロッパのことをメインにやっている人文系の研究者は細かい仕様に通じていなくても割と何とかなる傾向にある反面,東洋系はそうもいかない分詳しくやっている人が居ると思う.じんもんこんとかでもパーリ語文献のマークアップ方法についての発表などを聞いたことがある.
XSLT については困ったときあれこれ調べると IBM のナレッジベースがやたら引っ掛かることに定評がある (個人の感想)
JA:OSM XML - OpenStreetMap Wiki
https://wiki.openstreetmap.org/wiki/JA:OSM_XML
KML(Keyhole Markup Language) | Google Developers
https://developers.google.com/kml/documentation/kml_tut?hl=ja
KML - Wikipedia
https://ja.wikipedia.org/wiki/KML
あと文書形式でなくて良いなら、地図系の情報として OSM (OpenStreetMap) とか KML (地理・経路情報) とかも XML で表現されてますね。
でもこれはどちらかというと単にデータ構造の表現なので、人間用の文書形式とは別種の扱いになりそうだけど。

あーーー、 MathML と SVG の紹介を忘れてたわ
Mathematical Markup Language (MathML) Version 2.0 (Second Edition)
https://www.w3.org/TR/MathML2/overview.html
MathML は名前の通り数式を表現するためのものなんだけど、これは presentation markup と content markup という2つの方式を持っていておもしろい。
presentation markup は式の見た目 (表記) を素朴にタグ付けするもの (たとえば「式 ( 数値: 2, 演算子: ×, 数値: 3 )」みたいな) で、 content markup は数式の抽象構文木を XML に落とし込んだもの (たとえば「式:乗算 ( 数値: 2, 数値: 3 )」みたいな)。
HTML も MathML の埋め込みに対応してるけど、一部タグが競合する (そして HTML は名前空間の仕組みに対応していない) せいで、 HTML では presentation markup のみの対応になっている
W3C SVG Working Group
https://www.w3.org/Graphics/SVG/
SVG も概念としては素朴で、図形情報をビットマップではなく計算により再現できるアルゴリズムとパラメータで表現すれば拡大縮小回転その他に強くなるよねというやつ。
まあこれは広く使われていてググれば無限に情報出てくる
MusicXML 3.1
https://www.musicxml.com/for-developers/
MusicXML - Wikipedia
https://en.wikipedia.org/wiki/MusicXML
あと MusicXML という楽譜用のスキーマもあるのを思い出したけど、私はその界隈の人ではないのでどの程度使われているのかは知らない

This account is not set to public on notestock.
ぼくの大すきな ペトリネット
パパからもらった ペトリネット
とっても大事に してたのに
こわれて出ない 遷移ある
どうしよう どうしよう
XML におけるスキーマというのは「文書の構造や内容が満たしているべき制約」を記述したもので、有名どころとしては XML Schema と RelaxNG の二大巨頭がある。
(昔は DTD というのもあったけど、これはいろいろ不便で化石扱い。)
基本的に今から調べるなら RelaxNG のことだけ知っておけばいいけど、 RelaxNG でもデータ型として XML Schema の規格で定められたものを参照していることはある
あと Schematron という別の仕組みもあるけど、これは RelaxNG と組み合わせて利用されやすいとかなんとか。まあ必要になるまで調べなくていいと思う。
ともあれ、 XML 文書が本当に「妥当」かどうか (つまり中身がちゃんと解釈可能で意味付けされていて規格に準拠したものかどうか) を調べるためにスキーマが使われて、その検査を validation と読んでいる
文法エラーのない XML 文書は well-formed であると呼ばれるんだけど、それに加えて所定の (用途/形式ごとの) スキーマでの検査を通るものが valid であると呼ばれる
ちょうど syntax と semantics について別々に検査するみたいな感じの対応関係
quotations - Whence “emphasis mine”? - English Language & Usage Stack Exchange
https://english.stackexchange.com/questions/121560/whence-emphasis-mine


This account is not set to public on notestock.

This account is not set to public on notestock.

This account is not set to public on notestock.
This account is not set to public on notestock.
paragraph title を使って書いた記事の移行がつらいので section か何かを使って paragraph を無名にします……

This account is not set to public on notestock.
私はブヨグの検索あきらめて、記事ごとに0個以上のタグを設定する (そしてタグ同士は有向非巡回グラフを形成する) ようにした。
日本語でまともな検索は面倒すぎる。

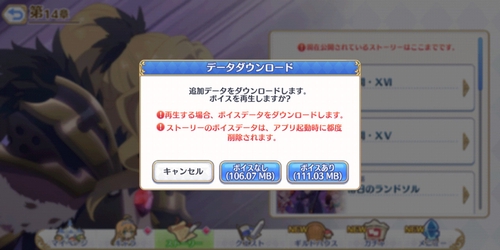
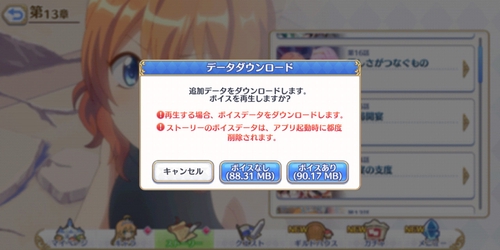
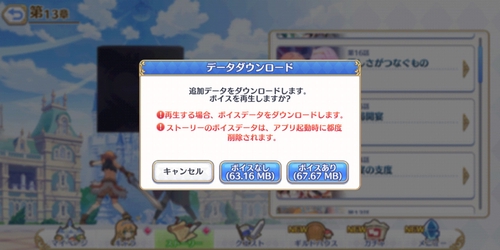
プリコネ、最初からプレイすると間に何回もダウンロード挟んでトータルで4GBぐらいはダウンロードすることになるよ。
#プリコネR 、電車の中でストーリー観るのに躊躇うくらいの容量のダウンロードが必要になったりするので、そっちをどうにかしてくれないと本編最後まで読めない
基本的に数 MB で済むけどたまにムービー付きのが数十 MB くらいあるので

アプリのデータ容量削減と、それに伴う仕組みの変更について【2019/12/11(水) 18:00 追記】 | プリンセスコネクト!Re:Dive (プリコネR) 公式サイト | Cygames
https://priconne-redive.jp/news/information/6795/
了解

1ヶ月 2 GB 生活をしているワイのことも考えてほしい (つまり家で事前ダウンヨッヨしたい)
やっぱりデータに迂闊にスクリプト入れるものじゃねえよ……