@Aqraf
https://friends.cafe/@inndoa/105365380718565303
https://odakyu.app/@h/105366040830590108
https://odakyu.app/@ars42525/105366070571049283
 Posting らりお・ザ・何らかの🈗然㊌ソムリエ(@lo48576@mastodon.cardina1.red)
Posting らりお・ザ・何らかの🈗然㊌ソムリエ(@lo48576@mastodon.cardina1.red)
@Aqraf
https://friends.cafe/@inndoa/105365380718565303
https://odakyu.app/@h/105366040830590108
https://odakyu.app/@ars42525/105366070571049283


Slack をクソの掃き溜めにするnの方法 - 何とは言わない天然水飲みたさ
https://blog.cardina1.red/2020/12/13/slack-good-stories/
IQ1 AdC にふさわしいクソ記事を投げた


This account is not set to public on notestock.
所属会社を SNS で明かしていない人による #いい話 を聞けたりすることもあるからね……
にっこりできる記事を目指しました (?)

弱酸性の洗剤を使った後だったけど待つのが面倒なのでヌメリ取り用に塩素系の漂白剤を使った
明後日になっても活動がなかったら塩素ガスで死んだと思ってくれ

This account is not set to public on notestock.
NeruPointerException
Slack をクソの掃き溜めにするnの方法 - 何とは言わない天然水飲みたさ
https://blog.cardina1.red/2020/12/13/slack-good-stories/
IQ1 AdC にふさわしいクソ記事を投げた

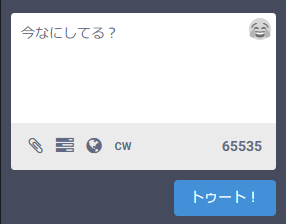
PostgreSQLのtextが許容する範囲でいくらまででも入れてしまえ

上限を65535文字にしたからといって本当に65535文字投稿するのはまず無いんだけど制限が厳しいこと自体がキモいんだよな
その辺りのことは昔ブヨグにちょっと書いたんだけど、「Mastodon 自体のデザイン (見た目ではなく設計のこと) は押し付けていくぞ」という姿勢が垣間見えるんだよな
サーバのカスタマイズを嫌がる姿勢というか。
「メディア最大サイズは固定!」とか「メッセージ長上限は固定!」とか言うだけなら一見すると連合を大事にしているように見えるんだけど、その上限の妥当性を判定するのが実装側で本当にええんか? というのは疑問です
そもそもの話、じゃあ上限値に各鯖缶やユーザが納得できる rationale があるのかというのもかなり微妙そうだし。
もっと言えば言語や文化ごとの違いとがガン無視でしょう
これは本質情報なんですが、無線ヘッドホンの方がバッテリーが入るので有線のものより重くなり、重くなるということはずりおちるのを防ぐために側圧が強くなります
WH-1000XM3 を着用していた後に MDR-1AM2 を使うと、毎回「羽のように軽い……!!」と思う
側圧が強いのが苦手とか長時間着用を想定するとかであれば、無線は慎重に検討した方がいい
まあ私は無線と有線の両方買ったわけですが (耳は4つもない)
まあ室内であってもノイキャンがすごいというのは確かにそうで、長時間の側圧に苦を感じないのであれば常時無線ヘッドンホホというのもアリな選択だとは思う

This account is not set to public on notestock.
65W とかの USB PD 充電器を買えば、めちゃくちゃ短時間で充電が終わるので「夜寝る前に充電器に……」とか考える必要なくなるよ
「おっ電池ないやん繋いどこ」ができるようになるし、途中で中断してもそれなりに充電されてる
違いがよくわからない (プログラムを外部から読み込むか否かに関係なく「電子回路を通すことで入力から出力が得られる」という構造は変化していないので)。
チューリングマシンと万能チューリングマシンみたいな話してる?
チューリングマシンは「入出力テープに対して特定の計算を行うもの」で、万能チューリングマシンは「入出力テープに乗せられたチューリングマシン情報を読み取って、そのチューリングマシンの計算をエミュレートするようなチューリングマシン」のこと
たとえば乗算の存在しない言語で加算とループとビットシフトを使って乗算を実現することは可能なんだけど、それをアンロールあるいは最適化あるいは全然別のアルゴリズムによってハードウェアで (ソフトウェア側からステップが確認できないようなパッケージ単位で) 実現することは可能だと思うのよね。
ただ、これらの間に本質的な違いがあるとは思えなくて、両方とも論理回路を通して計算している。
違いは中間段階が確認できるかどうかと、計算の順序や依存が入力データによって明示されるかどうかだけ

ソフウウェア処理とハードウェア処理はロジックがアプリケーションソフトウェアで作られているか、wired logic な回路で作られているかというだけで、どっちも本質的には計算機のプログラミングと同じですよ
精度が低いのは、単に double (f64) でなく float (f32) を使っている程度の話だと思うけど
もっと言うと、最近の CPU はマイクロコードというものを使っていて、「ひとつの CPU 命令が内部的な複数の微小命令 (マイクロコード) として実行される」という仕組みになっている。
つまり我々が単一の CPU 命令だと思っているものは、 CPU の内部的には複数の命令の列なわけ
マイクロコード(μOPs)とは - IT用語辞典 e-Words
http://e-words.jp/w/%E3%83%9E%E3%82%A4%E3%82%AF%E3%83%AD%E3%82%B3%E3%83%BC%E3%83%89.html
ワークロードと製品の価格帯によりそう (しらんけど)
GPGPU 想定のやつとかはさすがに fp64 でもそれなりに出ると思うけど
オフロードするなら計算単体が早くてもしょうがないからなぁ

RTX series なんかは モジュール別に FLOPS 値が別々に示されているのでどのワークロードかで本当に変わりそう
それはそう、というか説明になってないけど正しい
たとえば計算回路のすぐ近くにクソデカメモリがあるとか、計算回路が並列実行用に多数積まれているとか、有名なコーデックはワイヤードロジック (あるいは最適化された回路) で実装されているとか、バスが太いとか、いろいろな要因はあると思うけど
なんで GPU が映像処理に強いかというと、演算器の性質としてたとえば乗算とかに強いけど汎用的でない演算器、みたいなのをバカみたいな数並べたりして行列演算とかそういうのに特化した回路になってる、とかそういうアレだから、という感じですね(説明はかなり適当なのであれだけど
うーん……なんか前者と後者でレイヤーが違う話な気がするなぁ (間違ってはいないんだけど)
結局、何が「整数の和」で何が「H.264 の復号」なのかはデータの解釈なしには語れない問題だからかなぁ。
デジタル回路は内部的には「単純な計算用の素子 (わかりやすいところでは NAND) が並んでいる」という形だけど、その NAND もたとえば加算用と乗算用と除算用とでは別の繋ぎ方で回路を成している。
で、あらゆるデジタル回路で発生している現象というのは「なんか入力線に信号を突っ込むとなんか出力線から信号が出てくる」に過ぎなくて、それを整数と解釈したり映像と解釈したりするのは規約の問題。
あと単純に PC に搭載するアクセラレーターとして常に映像視聴に特化していることが市場のニーズになっているので、特定のコーデック(MPEG4 だとか)をデコードする wired logic が組まれた回路を載せてるのもある。
ウィンドウアクセラレーターとか言われててビットマップの矩形処理とかしてなかった時代のヴィデオカードも MPEG-1 再生するアクセラレーターがついてるのがひとつのウリだったし、3D 時代になっても MPEG-2 対応で DVD が再生できます、MPEG-4/H.264 対応で Blu-ray が……とそれをウリのひとつにしてきたからね
「H.264 を流すと生映像が出てくる」というのは、その「どういう 01 の入力信号をどのように H.264 であると解釈し、結果の生映像をどのように 01 の出力信号としてエンコードするか (そしてそれを利用するハードウェアやソフトがどう解釈すべきか)」という規約というか合意があって初めて意味を持つものなので
その点では「論理和の回路 (OR) に a と b を入力すると a OR b が出てくる」というのと「H.264 デコーダに H.264 入力を流すとデコードされた映像が出てくる」というのは、噛ませている解釈のレイヤーが違う。
というか前者はほとんど解釈を噛ませてない (せいぜい active low と active high のどちらにするか程度)
極論すれば電流云々も間違ってないけど、ディジタル回路として回路を見るとき電流云々のアナログではみない、みたいなとこある
アナログ計算機で、たとえばオペアンプをつかって電流のアナログな変化値で積分をハードウェアで計算する、といったことも可能だしかつてやられていたことでもあるけど、ディジタル回路の世界ではひとまず入出力は常にディジタルでしかみない気がする。
たとえば H.264 デコーダを使って論理和を計算することはできるのだろうし (ナンセンスだけど)、それは「0に相当する H.264 信号と1に相当する H.264 信号を定義し、出力信号を0と解釈する方法と1と解釈する方法を定める」ということで成されるはず。
なので「○○を計算する回路」というのは、その解釈を一緒にせずには語れない
ところでこれは P.V.W.v の順で行列をかけている HLSL コードの アセンブラ出力なんですが、 xxxx とか並んでいるのを見ると微妙な気持ちになってしまう
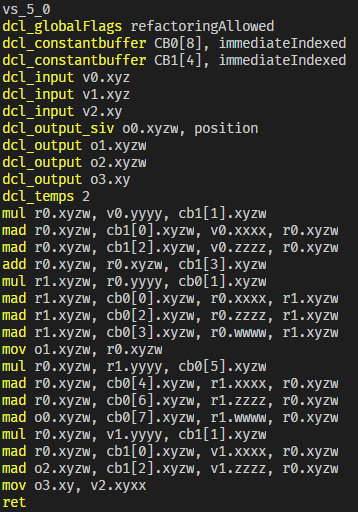

H.264, H.265 をひたすら勉強する秋を過ごしてきた身としては、 SIMD が多少は効きそうなのはわかるけど、でも相当に前のデータに依存するし、ハードウェアコーデック並列もりもり回路でドーンとは簡単にはいかなそうという感情でいっぱいになった
デコードはまあともかくとして、エンコードって何が支援されてるんだろう。パラメーター探索?圧縮?
パラメータ探索は、動きベクトル探索がダイヤモンド型に範囲を広めていったりとか、インター圧縮に使える参照画素の方向が30個以上あるだとか、まぁ30並列くらいできるとうれしい要素はありますね

This account is not set to public on notestock.
どういう意味だろう (ソフトウェアでなくハードウェアデコーダを使えるという意味なのか、フレームワークや API を言っているのか)
AV1 は一番時間かかるのがパラメーター探索ってドワンゴの例の記事に書いてあったけどそれは他のコーデックでも一緒なんかなあと思って
This account is not set to public on notestock.
AACS 2.0 の話やんけ (動画コーデックというかコピーガード)
Raspberry Pi の H.264 ハードウェアエンコーダーは B フレームかなんか入れられなかっただか可変にできなかっただかがあってあんまり……だったので、こんなもんかとおもった記憶ある
DVDFab Player 6 Ultraを使えばIntel SGX非依存でUHD Blu-rayの再生ができる - PCまなぶ
https://pcmanabu.com/pioneers-blu-ray-drive-can-not-uhd-copy-2/
一応 SGX なしでも計算でデコードはできるみたいね

まあ日本国内において合法なものか (=正規に AACS のデコードを許されたソフトウェアとして認証されているか) は知らんけど。
まああれは用途としてカメラの映像を圧縮するぐらいのつもりだっただろうから、録画データに使おうとした私がわるいけど
高速な計算のためには「どれだけ “素朴な” 解釈で入力を与えて出力を受け取るか」が必要になって、そして「特定の特徴を持ったデータを “素朴な解釈” で受け取ると、汎用計算に使いづらくなっていく」というのもあり、
これらを組み合わせると「特定の計算用に便利な回路を沢山積んだ “高速な計算回路”」ができあがる。
ハードウェアデコーダ高速化の論文とかあるので、それを読むとハードウェアコーデックが何であるかがわかりそう。僕はタイトルしか読んでないので中身が分かりません
や、 libaacs はリッピングでなくとも単なる円盤再生に必要だしそれは日本国内でも合法のはず
VideoLAN プロジェクトに感謝
ただエントロピー符号化器が過程やデコード状況に応じた確率分布の使い分けをやっているので、バンバン並列化できるという感覚があんまりわからない
映像をブロック化してそのブロックに対して云々みたいなことしてそうなので、ブロック単位でのある程度ローカルな計算の部分は並列化できるんじゃないかなぁとか思ったりした (実装知らず) (コーデック知らず) (完全に想像)
マルチメディア系のアルゴリズムは本当に必要に迫られないと勉強しない気がするなぁ。
深淵が深すぎる

Intel SGX ないと UHD BD 再生できないの独禁法とかでしょっぴけないかな
返礼品名 | 返礼品のご紹介 | 精華町ふるさと納税特設サイト【京町セイカのみんなでまちづくり大作戦】
https://furusato-seika.jp/goods/detail.html?id=6436bc3147dbfed640c6888171d0d0fe

This account is not set to public on notestock.
This account is not set to public on notestock.
@araigumaG あー確かに…… (というか libcss で外から鍵を拾ってくる必要があるのは知りませんでした (バンドルされてたのかな))
CSS がどうやって破られたか忘れたけど、たぶん AACS よりショボい仕組みだったので、どっかのレコーダーから万能のキーみたいなのが漏れたんだろうな
GPU 文脈でいうと draw command というのがあって、この command も単に命令というのとはちょっと違うニュアンスがある気がしますわね
instruction と command なぁ
instruction を命令として command は「指令」くらいか?
でも CPU 指示というのも弱すぎる気がして違和感がある (CPU は絶対に従うので)
でも XML の processing instruction (処理命令) は処理系が従うとは限らないので指示という感じがするなぁ
結局英語の方も十分ガバいので区別するだけナンセンスという話ではある
英語読めん!ってなった。参照フレームをDRAMに入れつつ、デコードしたいブロック周辺だけSRAMに持ってきてデコード、を多段パイプラインとして組むことで1フレームをがーっとハードウェアでデコードできるって感じだろうか? https://doi.org/10.1145/1118299.1118473 https://doi.org/10.2478/v10177-010-0039-7

"We use cookies to ensure that we give you the best experience on our website." じゃあないんだよ、 best experience が提供できない場合に何が何でも worst experience を押し付けようとするのをやめろ
NAL(H.264/H.265のパケットとしての単位)を解釈してバッファーに詰め込むところまでをソフトウェアからやって、その後が専用回路の出番かな? だからまぁ発端になったmp4(もともとコンテナだから違うとしても、ストリーム)のバイナリを回路に云々とはちょっと違うかな
Rust AdC (その1) の明日の枠が空いてたので飛び入り参加した

This account is not set to public on notestock.
町かどタンジェントにも特異点があるはず、つまり

This account is not set to public on notestock.
えー複素関数扱いしないとだめ? (だめとは)

This account is not set to public on notestock.
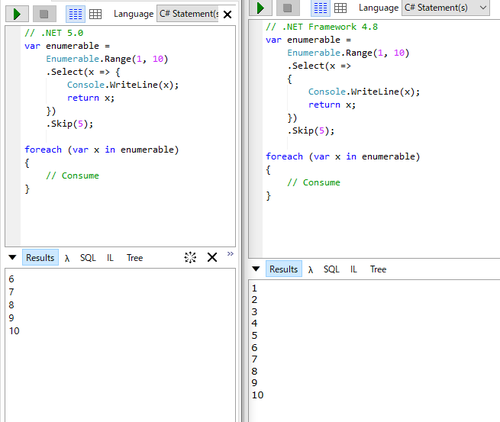
C# の LINQ も昔はすごい素直な挙動だったのに、 .NET Core では大胆に必要な部分しか実行されなくなったりしてるから、まぁあの手のメソッドチェーンでウェイってできるやつの map に相当する機能で順番通りに実行されることは期待してはいけないですね
Enumerable.Distinct の順序が保証されてない問題(保証されていないが破壊する実装が存在しないため、順序を仮定したコードを書いてしまいがち)
JS の linter があんなに発達したの、人がとりあえず解釈の間違えようのない安全なコードを書いた上で、機械に自動でプログラムの意味を変えないように可読性の高い書き方に変換してもらう必要があったからだと思うと悲しくて悲しくて
ちょうどこういうのがありましたね: .NETや.NET CoreのOrderBy(keySelector).First()はO(n log n)でなくてO(n)な件 https://qiita.com/RyotaMurohoshi/items/5b515bf2ee544cc1b016

C#、 ValueTask が登場した頃からパフォーマンスハックが高レイヤーにも見え隠れするのが気に入らない。ランタイムが隠蔽するべき案件が高レイヤーライブラリのシグネチャに現れてきているその妥協が気に入らない。互換性を捨てる気がないのに、中途半端な遺産を増やさないでほしい
意味論の規定がガバいのがつらいみたいなところがありそう (本当にこわい非互換はしっかり定義された本命用途の API ではなく「こうでもいいし、ああでもいい」という未定義部分に入り込む)
This account is not set to public on notestock.

This account is not set to public on notestock.
むしろ東京にいる人の方が現住居に思い入れのある人は少ないでしょ
田舎の方がそういう「地元への執着」みたいなの強烈なイミッジあるけど
チケット - コンテンツ鑑賞 - らりお Redmine
https://redmine.cardina1.red/projects/lo48576-contents-appreciation/issues?per_page=50
オタク、罪を積みがちわかる……
コンテンツ鑑賞 #145: 上倉雛のヒミツ - コンテンツ鑑賞 - らりお Redmine
https://redmine.cardina1.red/issues/145
泣いた
https://mastodon.cardina1.red/@lo48576/102876524633191050
https://mastodon.cardina1.red/@lo48576/105129695680255142
いま実家と現住所に罪が分散している (?)
なお ISO イメージは NAS に入っているので安心



This account is not set to public on notestock.