


へたにreasoningすると、どこかで「ハルシネーションを超増幅して発散する」ような現象も起きそうなもんだけど…どうなんだろうね。
 ぽな (C.Ponapalt)(@ponapalt@ukadon.shillest.net)の投稿
ぽな (C.Ponapalt)(@ponapalt@ukadon.shillest.net)の投稿 へたにreasoningすると、どこかで「ハルシネーションを超増幅して発散する」ような現象も起きそうなもんだけど…どうなんだろうね。
reasoning系モデルの思考ログを人の思考にあてはめてはいけない。あれは単なる最終出力候補を狭めるためのランダムウォークであろう。
しかしGPT-4.5では!上回りました!
…っていう前振りにも見えなくもない…
※そしてさらに後に出るかもしれないClaude 4 Sonnetに抜かれるオチもセット
ウチのサブスク契約がClaude推しのままなのは、言語理解能力の違いを普段から肌で感じてるのと、Deep Researchとかはそのうちオープンソースなフレームワークでできるやろと推定してるからなんだけど…
ベンチマークに現れないそういう違いが、実世界寄りのタスクで現れてきたのかなあ。
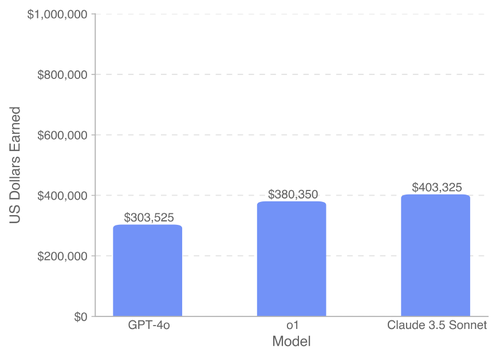
OpenAI からSWE-Lancerっていう、割と実世界に近いと思われるフリーランスのプログラマーのタスクをこなすベンチマーク(ベンチマーク結果は何ドル稼いだか!)が公開されたんだけど…
結果:
GPT-4o<o1<Claude 3.5 Sonnet
正直でよろしい 
着陸直前のウインドシアを制御しきれなくなってハードランディングって流れかなぁ。

映像追加されたけど、ポーポイズじゃなく単なるハードランディング・・・・><;
Accident Bombardier CL-600-2D24 Regional Jet CRJ-900LR N932XJ, Monday 17 February 2025 https://asn.flightsafety.org/wikibase/478376
