uaa@framboise:/usr/include$ echo ○1 |nkf -e |kakasi -KH -JH | nkf -w
○1
uaa@framboise:/usr/include$
変換できないものは素通しか。
 Posting SASANO Takayoshi(@uaa@social.mikutter.hachune.net)
Posting SASANO Takayoshi(@uaa@social.mikutter.hachune.net) OpenBSD(uaa@), Ham(JG1UAA), Ingress(Lv14, RES), Japanese(Sagamihara-city, Kanagawa)
Another side: https://social.tchncs.de/@uaa
npub1rarr265r9f9j6ewp960hcm7cvz9zskc7l2ykwul57e7xa60r8css7uf890
Messages from this Mastodon account can read via mostr.pub with npub1j3un8843rpuk4rvwnd7plaknf2lce58yl6qmpkqrwt3tr5k60vfqxmlq0w
uaa@framboise:/usr/include$ echo ○1 |nkf -e |kakasi -KH -JH | nkf -w
○1
uaa@framboise:/usr/include$
変換できないものは素通しか。
https://www.unicode.org/Public/MAPPINGS/OBSOLETE/EASTASIA/JIS/JIS0208.TXT 自体はUnicode Term of Useに従うとして、派生物もそれを継承するって理解で良いんだろうか?
いちいち書くのが面倒なのでSPDX-License-Identifier: Unicode-TOUと書くけど。 https://spdx.org/licenses/Unicode-TOU.html
kakasiはUTF-8に対応するものの、kakasidictはEUCで書かれているが故にEUCの範囲でしか漢字→かな変換はできない。【】などの記号類や全角英数字に対する読みも未定義。
…ってことは、UTF-8をそのまま食わせても良いんだけど、処理可能な文字が含まれているかどうかのチェック+EUC化みたいなフィルタを入れた方が安全なのかもしれないな。
ASCII(0x00-0xFF)の範囲は蹴るようにしていたけど、JISのひらがな・カタカナ・漢字以外の部分(記号とかアルファベットとか)も蹴った方が良いのかもしれない。

getwcをwchar_tの変数で受ける(正しくない)コードでもwchar_tがsignedなシステムならWEOFが-1でなんか偶然うまくいくかもしれない
OpenBSDにおいては、wchar_tはintと定義されてるみたい。負のキャラクタコードもアリなのか…(無いよね?)
ああ、思考を垂れ流しにしていますが実行するかどうかは別問題ですのでー
でもdata.arpaを見るに、
-2.131363 おたく/オタク ?/? -0.072304
みたいに変換できなかったものも平然と?で出てくるので、あまり厳しいことをしても意味は無いのかもしれない。
とりあえず何が削られたか、という一覧も要確認か。
obsoleteだが…ここに定義されている文字が含まれていない(UTF-8→JISへの変換ができない)エントリは無条件で除外、ただし<S></S>の類は除く、みたいな処理にするか?変換テーブルは https://www.unicode.org/Public/MAPPINGS/OBSOLETE/EASTASIA/JIS/JIS0208.TXT を使えば良いかな…
libkkc-data(のdata.arpa)が如何にして作られたか、という作り方がどこかに書かれていれば、その作り方で適当なコーパスを食わせて…ということができるんだろうけど、無い以上は模索するしかない。作者に聞けばすぐに答えが出てくる問題という気もするけど。
uaa@DESKTOP-251U0UF:/mnt/e/corpus/nwc2010-ngrams/word/over999/3gms$ echo "かな 漢字 ヘンカン" | nkf -e | kakasi -KH -JH| nkf -w
かな かんじ へんかん
uaa@DESKTOP-251U0UF:/mnt/e/corpus/nwc2010-ngrams/word/over999/3gms$
kakasiでまとめて処理、で良さそうだけど…UTF-8非対応って辺りがまた難易度高いな。kakasiで処理が難しそうなデータも、事前に切っておく必要があるんだろうね。
でもsrilmの出力は<s></s>化されているので、ここは気にしなくて良いかな…?
多分問われないとは思うんだけど、日本語webコーパスは</S>、libkkc-dataのdata.arpaは</s>なのでこの辺も似せておく必要がありそうな気がする。
ngram-format http://www.speech.sri.com/projects/srilm/manpages/ngram-format.5.html を見るに、ngram 1=n1のn1はエントリ数になるから、後加工でも大丈夫そう。あと、多分半角英数とか記号だけといったデータは元データから省いた方が良さそうな気がする。
なんだろうこれ…
鼻 で 息 4389
という元データを、
はな/鼻 で/で いき/息 4389
みたいな形に加工してから食わせるのか、あるいは出力された3gram.txtの結果を処理するのか(でもARPAヘッダの存在を考えると元データ側に手を入れてそうな気がする)
出現頻度1000以上の形態素N-gram(3-gram)をsrilmで処理するのにかかった時間は3分くらい。出力された3gram.txtはARPA形式なので、冒頭が
\data\
ngram 1=236180
ngram 2=5654587
ngram 3=1355192
\1-grams:
-4.257625 " -0.3292079
-7.02774 "" -0.2590316
となってる。一方、libkkc-dataのdata.arpaは
\data\
ngram 1=118333
ngram 2=775414
ngram 3=1777469
\1-grams:
-2.105448 </s>
-99 <s> -0.203198
-4.499434 ’/’ -0.277539
-5.607917 ’’/’’ -0.262133
-5.793264 ’・/’・ -0.118066
…コーパスをそのまま食わせるのでは多分ダメ。
…ノウハウの確立にそこまでデカい(取り回しの悪い)データ使う必要、無いんじゃないのかなあ自分。
日本語ウェブコーパス2010の、頻度100以上を使っているけど…1000以上で始めた方が…?>自分
xzcat *.xz > 3gm
~/srilm/bin/i686-m64/ngram-count -order 3 -text 3gm -lm 3gram.txt
一体何が出てくるのやら
実は"abc"[1]の代わりに1["abc"]なんて記法ができるなんて、今の今まで知らなかったです…知ったところで使いようがないんですけど。
難読化の話(超!?入門編) (2018/07/26) https://netagent.co.jp/study/blog/hard/20180726.html で紹介されていたUnderstanding Misunderstandings in Source Code https://atomsofconfusion.com/papers/understanding-misunderstandings-fse-2017.pdf 、Table1の「べからず例」は結構やってしまっている箇所があるな…まあstyle(9)で{}の括り方が規定されている以上、これについては言ってくれるなというのがあるけども。
if (4 % 2)みたいな0→falseを前提としているとか、三項演算子は結構好んで使ってたりする。

表に出ないソースコードは難読化なんてしないけど、web領域だと見えちゃうことを避けられないみたいだし…開発時は普通に、webサーバ上に上げる時は難読化するとかそういうことくらいはしていてもおかしくない気が。

This account is not set to public on notestock.
SystemGear製の抗菌磁気カードリーダー(PDC-30) https://www.systemgear.com/prd/magneticcard/pdc30/pdc30.html に見えますね…面白そう。

アキバはこういうのだよな!ちゅった。が、なんに使うんやこれ

SXGAからFullHDへ移ってはみたけど…確かに最近、手狭になってきたような気がする。80×30字のコンソールを6つも開けるようになったのは確かに広いっちゃ広いんだが…それだけ開いてる訳でもないし。

This account is not set to public on notestock.
This account is not set to public on notestock.
デバイス系よりweb系の方が、ソフトウェアによるソフトウェアのって部分があるので色々介入しやすそうですね…最悪の場合、ブラウザに手を入れて動きを見るなんてこともできそうですし。
んー…
https://js.gsspcln.jp/t/399/201/a1399201.js はかるーく難読化かけてるみたいだけど
https://works.gsspcln.jp/w/ad_format/gnScrollCatch_multi.js ってそういう小細工してないですよね。
こういう手合いについては詳しくないんですけど、この前マクドナルドで飯食ってた時に「素性を抜かれないようにあれこれ細工するのが基本」って女子高生が言ってた気がします。
自分みたいなシロートにどこどこの企業か…なんて突き止められるのって、その基本ができてないってことなんですよね?
悪名高きスクロール妨害広告を解析する (2023/8/25) https://qiita.com/reika727/items/5a3cbdd211f79f82fdd5
Javascript中に出てくるgsspcln.jp、whoisすると http://geniee.co.jp/ が連絡窓口って出ますね…


悪名高きスワイプ広告を解析する(2023/8/10) https://qiita.com/huzisuke/items/cdc63b4bf9d2ded5b5ca
このスワイプ広告は本当にウザくって、作った人間ごと滅ぼそうぜって日々思うんだけど…どうせ滅ぼしたところでもっとタチの悪いのが出てくるんだろうなとも思う。
自分の端末だと、これが表示されると記事をスクロールできなくなる(スワイプ広告を上下にスワイプしてもどかすことができない)ので本当に邪魔なんだよね。広告の脇に少しでもマージンがあればまだマシなんだけどそんなのは当然無いし。

それにしても、GNU/non-GNUの文脈で語られてしまうというのはちょっとどうなのって気はする。
コンパイラだっていつまでも提供され続ける訳じゃないのだから、違うコンパイラでも動かせるようにするという試みって、思想(ライセンス)の問題よりもはるかに重要だと思うんだけど。
Chimera Linux https://chimera-linux.org/ がそれっぽいな
非 GNU な Linux ディストリビューション (2023/2/15) https://linux.srad.jp/story/23/02/14/190237/
A Non-GNU Linux Distribution Built With LLVM & BSD Software Aims For Alpha Next Month (2023/2/6) https://www.phoronix.com/news/BSD-LLVM-Linux-Alpha-Coming

GNUあってのLinuxなのでデフォルトのコンパイラはgccを使い続けるんだと思うけど…カーネルからユーザランドまですべてclangで構築したLinux distroってあるんだろうか。
LPCNet、ベンチマーク取り直して後はぶん投げる(SSE4.1をデフォルトにするか、今まで通りAVX主体でいくかを決めるのはこっちじゃないし…Pentium G4600持ちな身としてはSSE4.1がデフォでいーじゃんとは思うけど)。

uaa@slackware-vm:~/LPCNet.drowe67/build.sse/src$ time cat test.out | ./lpcnet_dec -s > /dev/null
direct split VQ
dec: 3 pred: 0.00 num_stages: 4 mbest: 5 bits_per_frame: 52 frame: 30 ms bit_rate: 1733.33 bits/s
64 1 1 16 128 1152 160 160 160 160
ftest cols = 2002
real 0m10.858s
user 0m10.753s
sys 0m0.085s
uaa@slackware-vm:~/LPCNet.drowe67/build.sse/src$
slackware付属のgcc-11.2じゃなくclang-13でビルドしたら、i686でもなかなか実用的なパフォーマンスが出ますね…
※どういうお仕事をしているかはなんとなくバレていると思っているし、web日記のどこかにきちんと書いてあるからいちいち書かなくても大丈夫ですよね…?(なので尋ねられても言葉を濁します)
ま、お客様なら敬語で遇されて当然、な意識の染みつきまくってるネイティブ日本人にこの考えは到底受け入れられないだろうとは、思う。
接客業なお仕事をしている身としては、高齢者とかちょっと認知症入っちゃったような人だとやさしい日本語レベルまで情報量減らさないと伝わらないという現実があるし、そういう人達が増えてるならもうデフォルトがそのラインで良くね?って気がするんだよね。
労働者が少ない、その割には客が多い(なんかまた増えてるらしいじゃん色々と)となると、減らせる労力は減らして提供すべきサービスをきちんと提供できる体制にしないと滅んでしまうんですよね、みんなが。
「⑩ 相手の日本語の力が高い場合は「やさしい日本語」を辞める」どうなんだろうこれ、相手の日本語力が高ければ「それは『やさしい日本語』」と解釈してくれる以上問題無いのでは…?と考えてしまうんだけど。
どっちかっつーと、「やさしい日本語」を基準にして、相手に応じて言葉を盛っていくというスタイルが標準、の方が良い気がする。日本語苦手そうだからやさしい日本語on、ネイティブ日本人だからoffというのは、自分の感覚ではなんか違うなーと感じてしまう。
やさしい日本語(医療×「やさしい日本語」研究会 )(2021-05-24?) https://easy-japanese.info/about-easy-japanese
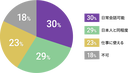
「〇〇が好きなやつには申し訳ねえが、俺は〇〇が大っ嫌いなんだ、誰が何と言おうとな。だがまあ〇〇が好きなやつが〇〇が好きだということに対して否定する気も無いし、俺が好きになれない〇〇を好きでいられるというのは正直羨ましいぜ。」って辺りで、どーよ。
お気持ち→感情論じゃねえか(本文中にもそう書いてある)
なるほど、腑に落ちた。「お気持ち表明には善悪を持ち込まないことを徹底してください。「こんなの正しくないよ」ではなく「こんなの嫌いだ」です。(中略)私は好き嫌いの話しかしていないけど正しいのは私だぞの気持ちでいれば大丈夫です。」
今日から始めるお気持ち学 (2022/3/12) https://note.com/noty_ice/n/n4b3e28f465bb
実は「やさしい日本語」程度の情報量で足りるのかもしれない。敬語が使えないから人間失格!死ね!殺せ!とかならないで済むわけだし。
積極的に意思疎通プロトコルの破壊を目論んでいる輩も多そうに見えますねえ…(空気を読め、というのも一種の意思疎通プロトコルの破壊に思えていて、言語*外*という具体的な定義の無いものに意思疎通を大きく委ねてしまっていることを正当化するのは非常に危険だと自分は考えてしまう)

オブラートなしで言ってしまうと、誤用や新しい用法それ自体を問題視しているというよりは、「誤用も新しい意味になる」とか言って意思疎通プロトコルの破壊行為を正当化して自己弁護してしまうそのメンタルこそが信用に値しない、だからこそ擁護への不寛容のあらわれとして誤用という表現を使う、みたいなところがある
まいじゃー推進委員会の全盛期が懐かしいのぅ
個人的にはとらドラよりも田村くんだなあ…

This account is not set to public on notestock.
This account is not set to public on notestock.