@teobot gRPC を滅ぼしてる画像持ってない?

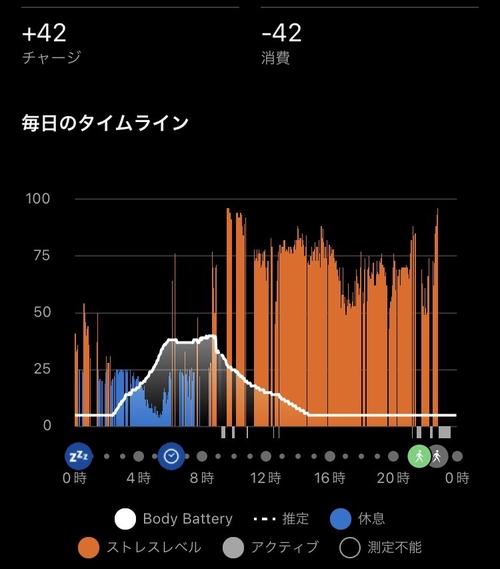
ABORT: とかだと JMP 0 使ってるし、JP 使ってるところも何らか後ろに続く処理をするかどうかの if 分岐みたいに使ってるようにしか見えないのでこれは混同とかじゃなくて実際に意味のある判定してるんじゃないかという気がしないでもない。偶パリティ判定というよりは値の popcount をした結果の偶奇判定、という見方で何か意味あるアルゴリズム読み解けたりしません?(ちゃんと読んでないからわからないけど

This account is not set to public on notestock.

This account is not set to public on notestock.

関東、濵かつないの?マジ?東京にはなんでもあるって聞いてたのに濵かつないじゃん
とんかつ大學にはどうやら入学できなさそうだが、豚大学とんかつ学部は都内にあるようだ >> 豚大学とんかつ学部 | 豚大学公式サイト
https://butadaigaku.jp/tonkatsu/
リンガーハット系列のとんかつ屋はもう関東にひとつもないことがわかった、去年に存在知ってれば大森なら行ったのに……
“この度、長きに渡りお引き立ていただきました「とんかつ大學 イトーヨーカドー大森店」ですが、諸般の事情により2023年5月7日(日)をもちまして閉店いたしました。
”
(2022/02/24) リンガーハットグループの「とんかつ濵かつ」が岡山県以東唯一の店舗「JRお茶の水店」を3月に「とんかつ大學」へ転換 「とんかつ濵かつ」は中国地方11店舗、九州72店舗に - ネタとぴ
https://netatopi.jp/article/1390747.html

kb10uy 氏の kb([:digit:]{2})uy の \1 部分、最近いろいろ変わってるの何の数字なのか気になっている
いいかい学生さん、トンカツをな、……なあ、この話メンチカツでやり直しちゃダメか?
@akahana まあ Creative のいう「ハイエンドスピーカーのように自然な立体感」はだいぶウソだろと思うけど最近のサウンドバーも TV 内蔵スピーカーもみんな、それ単体で真上や真後ろから音が聞こえてくるかのように誇張して広告してるしこれもまあ気持ち音場が広がって聴こえるとうれしいねぐらいそうではある
@akahana あと PS5 や最近のサウンドバーは本体にインパルスの音波を部屋じゅうにスイープしてそれをコントローラのマイクでや本体のマイクで録音して、それで部屋のインパルス応答特性とかから反射や残響を計算して自動で立体音響補正かけたりするね
@akahana ソニーはさっきの耳の写真撮るやつだけでなく PS5 のほうでも多少は考えていて、多数のサンプリング結果から HRTF をおおまかに3系統ぐらいでモデリングしてユーザーに3つのうちどれがいちばん立体感あるかを選んで使ってもらえるようにしてる
https://av.watch.impress.co.jp/docs/series/rt/1323407.html

@akahana ただ、ここらへんいずれも標準的な HRTF を使うだけなはずで個々人に合わせてテーラーメイドできてるのはソニーだけだったとおもうから、Creative のようなオーディオに詳しくないゲーマー寄りのメーカーから出てきたことには意義がありそう
@akahana あと Apple Music や amazon music もハイレゾ配信と並行で Dolby Atmos ミックスの配信やってるし、Apple のヘッドフォンやイヤフォンも「空間オーディオ」機能で勝手にステレオを擬似サラウンドにするわね https://support.apple.com/ja-jp/guide/airpods/dev00eb7e0a3/web
@akahana いまは映画も Dolby Atmos をウリにしてるし、Windows 10/11 もデフォルトでサラウンド効果 DSP 処理みたいなの内蔵してる上に金払えばここを Dolby Atmos や DTS-X に切り替えられるし、家庭用 TV も国内メーカーはみんな軒並 Dolby Atmos の擬似サラウンド効果内蔵して、ゲームでもここらへんを使う(PS5 の Tempest Audio、Xbox Series X の Dolby Atmos)のがデフォルトなのでもう勝手にサラウンドになってるまである

This account is not set to public on notestock.
@akahana 最近は Dolby Atmos 対応とかで ThinkPad X1 Carbon のステレオスピーカーですらここらへんの DSP 処理でかなりうまいこと擬似サラウンド処理をする(というかステレオシステム自体、モノラルに対してのサラウンド化ではある、左右の音量差や位相差や時差を使えるようになるだけでかなり音の位置をあちこち動かせるため)ので、Creative がこれをスピーカーにも適用できるように、というのもまたまあそうですねという感じあるね
@akahana ソニーも 360 Reality Audio で似たことしてる https://knowledge.support.sony.jp/electronics/support/articles/00233341

@akahana が、HRTF は当然ながら、高額な測定環境を揃えて個々人でそれぞれ測定しないと正確なものはわからないので世のシステムは大抵平均的な人々のそれを近似したものを使っているので、擬似サラウンドがちゃんとそう聞こえるかは人によってかなり個人差がある、というのを、HRTF と頭部画像を紐付けた教師データから回帰分析とか学習させたら画像から HRTF 吐かせる何かは作れそう
@akahana 人間の耳に音波が伝達するとき、頭や体、耳の形状で反射や減衰がかかったものが鼓膜を通じて脳に入力されて人間はこの入力から長年の学習で音の立体感や方向を認識するので、ヘッドフォンから原音そのまま鳴らすとこの学習と齟齬のある音が入力されて頭の中あたりに音が定位する、というのがまずあって、そこで原音が鼓膜あたりにきたときどう変化するのか表したのが頭部伝達関数 (HRTF) で、擬似サラウンドはいってしまえばこれや左右での時差や位相差を利用して脳にサラウンドだと思わせている
@akahana 頭部伝達関数を画像から推定してそれを逆算した音を出すってことでない?

This account is not set to public on notestock.