百合ブック情報と言えば,SF で有名な早川書房が来月下旬からハヤカワ文庫百合 SF フェアやるから絶対買おうな

百合ブック情報と言えば,SF で有名な早川書房が来月下旬からハヤカワ文庫百合 SF フェアやるから絶対買おうな
スマホやPC本体に「著作権料上乗せを」国際組織が決議:朝日新聞デジタル https://www.asahi.com/articles/ASM5Y6WJGM5YUCVL01Y.html

このアカウントは、notestockで公開設定になっていません。

このアカウントは、notestockで公開設定になっていません。
このアカウントは、notestockで公開設定になっていません。
べつに学会とかで適当に取り分けるのに盛り付けはどうだって良いのだけど,それはそれとしてあれをうまそうな盛り付けと評せるのはなかなか独特のセンスなのでは
「王の写本」の覆刻版とかって刊行されてないんかな。手元の訳書と対比させて読みたいよね
@jnsk 現代に残ってる『エッダ』からはそう解釈されてるね。とはいえ『エッダ』は長らく吟遊詩人の詩としてサーガと一緒に口伝で伝えられてきてて,テクストになったのが中世になってからでキリスト教や当時の事績なんかに影響されて混ざったりしてるので,もっと古い形の北欧神話だとどうだったかは謎に包まれてます……。
白鳥の路→海
枝の破滅→火焔
荒野の住人→狼
蛇の臥所→黄金
剣の戯れ→戦
こういう言葉遊び面白い
@jnsk 註・バルドルはまだ若かったヤドリギだけとは契約してなかったのでヤドリギだけはバルドルを傷付けることが出来たので,ロキの悪戯で唆されたバルドルの盲目の弟ヘズがそうと知らずにヤドリギの槍ミストルテインを投げてバルドルは死んでしまう。世界中の物がバルドルの死を嘆いたら復活させてもらえるよう交渉したが,老婆に化けたロキが悲しまなかったのでそのまま死の国に囚われていた。
@jnsk 詩によっては,人間も男女一組だけこっそり生き延びてた,だけど運命を司る女神ノルンである,ウルズ・ヴェルダンディ・スクルドの三姉妹が死んだので,人間は未来がわからない世界を生きている,という教訓めいた話にされてることもある
@jnsk だけどオージンの息子のヴィーザルが戦に備えて作ってた靴をフェンリル狼の口のつっかえ棒にしてそのまま口を裂いて殺して,世界が焼けおちた後も生き残り,また,世界中のものたちに祝福され不死を得た美しい男神であるバルドルも地上に帰ってくる,と言われている(これはキリスト教の影響が指摘されている)
@jnsk で,来る戦いに備えて,戦乙女ヴァルキリーは戦場の英雄を英霊エインヘリヤルとして回収してヴァルハラに集めてるし,オージンはそのために恣意的に地上に戦を起こしたり,やりたい放題なんだけど,結局豫言通りになります
@jnsk 巫女の豫言で,オージンはフェンリルに太陽共々喰われ,雷神トールは世界蛇ヨルムンガンドを倒すも数歩後退したところで毒が回って相討ち,神々の国アスガルズへの入口,虹の橋ビフレストを年中不朽で監視し,来る終焉の戦の際には角笛ギャラルホルンを吹く役目を持つヘイムダルも稀代のトリックスター・ロキ神と互いの頭を互いの足が貫いて相討ち,ムスペルヘイムからやってきた火の巨人スルトが世界中を火に焼べて何もかも焼けておしまい,というのが神々たちも最初っからわかってる
王侯を指す言葉として「腕輪をこわす者」があるらしい(北欧神話だけじゃなくてベーオウルフにもある表現)
神々,ラグナロクに備えてる話めっちゃ語られるけど,実際のところうっかり他人に自慢の剣をあげちゃったから最終決戦は牡鹿の角で参戦します!とか舐めとんのかみたいなヤツらばっかでそら相討ちだわみたいな気持ちになってきた
@boronology 古い英語の綴り本当多すぎるから統一してくれ〜〜〜って思ってたらクソみたいな綴りの現代英語を見せられる回

このアカウントは、notestockで公開設定になっていません。
谷口先生の『エッダ—古代北欧歌謡集』だと「枝の破滅」が「火焔」を意味するケニング,と書いてあったのでもはや剣ですらない可能性あるな
吟遊詩人たちは同じ語彙を用いることを極端に嫌ったのか,北欧神話の主人オージンのことを指す語も 10 や 20 じゃ効かないくらいたくさんあるっぽい
よく JRPG にも出てくる,北欧神話のムスペルヘイムの火の巨人「スルト」が持つ武器,レーヴァテインが,直訳すると破滅の枝で,実はケニングなので実際はただの剣としか言ってなくてべつにレーヴァテインという魔剣の固有名詞のつもりで書かれたわけではない,という研究がある(あくまで研究の一説だそうですが
ヴァイキングとか北欧で熊の毛皮を被る戦士居たりしたんだけど,berserk(ベルセルク,バーサク)というのはまさしく熊の毛皮を被った戦士,という意味の古ノルド語からきてるし,beowulf という語は現代の bee(蜂)wolf(狼)と同じ語源の語の合成で,直訳すると蜂に向かう狼,なのだけれども,これはケニング(古代〜中世の北欧や古英語などゲルマン民族の散文に見られた詩的な修飾法。たとえば「破滅の枝」という語で剣を比喩するとか)では熊を表す暗喩語なので,berserk との共通点が指摘される
そういえば,𠮷野家って公式サイトや公式アカウントもつちよし使わないんだなあ。機種依存文字とかの時代はともかく現代の Unicode 前提の環境だと問題なさそうなのに。

このアカウントは、notestockで公開設定になっていません。

このアカウントは、notestockで公開設定になっていません。

このアカウントは、notestockで公開設定になっていません。
2013 年の冬に mikutter で艦これやろうとしてとしぁさんに騙された(許さんぞ
IIS 7.5 ということは Windows Server 2008 とかだし,そら改竄のひとつやふたつはされますわな。
ヤマダ電機,会員登録で空メール飛ばさせるみたいなフィーチャーフォン時代の遺物みたいなシステムあくまで昔からの経緯でそうなっただけかと思ったらガワも普通に古いんかい
わーほんとに IIS 7.5 だ >> Site report for ymall.jp https://toolbar.netcraft.com/site_report?url=https%3A%2F%2Fymall.jp
上坂すみれ:「スター☆トゥインクルプリキュア」で5人目のプリキュア声優に 「まさか自分が…」 - MANTANWEB(まんたんウェブ)
https://mantan-web.jp/article/20190530dog00m200065000c.html

学生プラン申請した後に priv. repo. 無料化来たしあの申請のおかげで PRO 扱いになってるのかな
端書きくらいなら priv. repo. の Wiki とかじゃなくても Gist の secret で十分なんだよな。
最近少し Rust 修行してるから競技プログラミングも Rust でやるようにしたいと思いつつできてない
なんか気がついたら私の GitHub account に PRO って書いてあったし private repository の wiki に研究メモとかドキュメント書くみたいなのやるんだけど,あれ PRO じゃないと使えないのかと驚いている
激辛系のカップ麺の新作つい買っちゃうんだけどカップ麺を普段食べないからそのままストアしてしまうな

このアカウントは、notestockで公開設定になっていません。

このアカウントは、notestockで公開設定になっていません。
このアカウントは、notestockで公開設定になっていません。
このアカウントは、notestockで公開設定になっていません。
このアカウントは、notestockで公開設定になっていません。
このアカウントは、notestockで公開設定になっていません。

このアカウントは、notestockで公開設定になっていません。

現行のスマーヨウォッチ、5〜6年前に出てたロー〜ミドル向けのCPUに、より低性能なGPUとウェアラブル周りの機能載っけてコネコネして、更に512MBしかないメモリ上でアンヨヨイヨ8のような何かが走ってるので、その辺を察しつつ触るとまぁ悪くない感じ。
このアカウントは、notestockで公開設定になっていません。
Wear OS って iOS に対する watchOS みたいなやつの Android 版か
データ構造アライメント - Wikipedia
https://ja.wikipedia.org/wiki/%E3%83%87%E3%83%BC%E3%82%BF%E6%A7%8B%E9%80%A0%E3%82%A2%E3%83%A9%E3%82%A4%E3%83%A1%E3%83%B3%E3%83%88

そう,そゆの。しかしカーネル内 malloc は見た目通りの簡素な実装で安心するな……。
このアカウントは、notestockで公開設定になっていません。
なので C で構造体を作ったとき,構造体のメンバ同士は必ずしも連続してなくて,たとえば char の と int でメンバ二つの構造体でも 3 バイトじゃなくて 1 バイト変数,3 バイトの詰め物(padding),4 バイト変数,の合計 8 バイトとかの可能性が高い
メモリアクセスの効率化のために,メモリ確保するときは 2 の倍数のアドレスから始まる位置になるようにズラしたりして揃えるからです(これを align と言う)
このアカウントは、notestockで公開設定になっていません。
@babukaru まあ GPU にテクスチャやポリゴンの座標情報は転送しないと GPU 計算してくんないからそゆのは malloc したりしてるとは思うけど,さすがにいちいち free してまた malloc まではしてなさそう。とはいえ,そこ以外でもたとえば printf するだけで malloc 走ったりするし実は全体でみると malloc/free は思ったよりは繰り返されるね。
スワップファイルの話と memory manager がアプリごとに用意してる仮想メモリの話はちょっと別の話なので……。
nmapで確保してくるメモリのもとは物理的にどこにあるものなんだろ。スワップファイルそのものなのかしら。
@babukaru 昔の bitmap 画像で描画してるやつはマウスポインタ動かす度に一度画像を消してマウスポインタを動かしたビットマップ画像作ってそれを画面に出して,をやるからそうなっててもおかしくない。現代の X は DRM 使ってて,X の描画機能はガン無視してアプリは OpenGL ES でウィンドウを描画するし,コンポジット型の WM はアプリが描画した内容をテクスチャとして貼り付けた板のポリゴンをひとつのウィンドウとして,ポリゴンの重ね合わせを計算して描画するからほとんどは GPU がうまく計算してくれる。
このアカウントは、notestockで公開設定になっていません。
さっき貼った動画のスライド資料 >> Glibc malloc internal
https://www.slideshare.net/kosaki55tea/glibc-malloc

@babukaru 大昔の Unix の命名規則そのまま受け継いでるからなあ。三文字略語が多いので source,destination じゃなくて src,dst とか。まあこれは man で libc の関数みたときもそうなんだけども。
小崎さんことがちゃぴん先生の malloc 動画本当にわかりやすいので神 >>
"The 67th Yokohama kernel reading party" を YouTube で見る
https://youtu.be/0-vWT-t0UHg

malloc,C で実装してるし管理用のメタデータを構造体で定義してるはずなのに,高速化やメタデータ領域節約のために C で宣言した構造体の構造をガン無視してその領域にアセンブリでアクセスして,たとえばあるメンバ変数の一部のとこだけをビットマップとして使うみたいな黒魔術だらけ
@babukaru いまかるばぶさんが貼ったのはどっちもユーザーランド malloc だから first-fit とかじゃない algorithm だと思うけど,基本的に *BSD よりも Linux や GNU 実装ユーザーランドのほうが高速化や拡張による高機能化のせいで死ぬほど複雑化しがちなので勉強で読むには *BSD のがらく
@babukaru 普通 heap は足りなければ brk システムコールで増やせるのだけど,glibc の malloc はある容量以上の領域が必要になったら heap じゃなくて mmap システムコールで確保した別の領域を使ったりします(mmap はあるファイルをメモリの上に map するときなどに使う目的のものですが)
@babukaru malloc はカーネル内 malloc(BSD だと libstand とかに実装されてそう)とユーザーランド malloc があって,前者はメモリ領域を一次元リストで管理して,確保するときはリストを先頭から手繰って最初に見つけた空きを使う(first-fit という algorithm)みたいな素朴な実装だったりするけど,後者は高速化や省メモリ化,マルチスレッド化と様々なニーズに応えた実装になってて死ぬほど複雑
危険性高いウイルスの取り扱い 住民に伝達 国立感染症研究所 | NHKニュース
https://www3.nhk.or.jp/news/html/20190530/k10011935201000.html
こう紙巻きはダメ,加熱式はオッケー,というのは常識的に考えたら葉巻,パイプ,煙管,シーシャなどもダメなんだろうけど,わざわざ紙巻きだけ名指ししてるの面白い。まあ紙巻きがほぼ 100% だからだろうけど。
タイトルの話よりボヴさんのルノアールこぼれ話ネタのほうが面白すぎてこれが本題だと思う。 >> 喫煙席が魅力の銀座ルノアール、よりによって紙巻たばこ禁止へ : 市況かぶ全力2階建
http://kabumatome.doorblog.jp/archives/65942655.html


 の投稿
prime@mstdn.poyo.me
の投稿
prime@mstdn.poyo.me
このアカウントは、notestockで公開設定になっていません。
128-bit だとメモリアドレスと IPv6 アドレスが 1:1 に対応できるみたいな電波を受信した(できるからなんなんだ)
そういえば Intel アーキテクチャだと結局 48-bit じゃない。Aarch64 とかだとどうなってるの
たけおかさんのスライドで気がついたんだけどプログラムカウンタが汎用レジスタとして実装されるのは特許なんですね……。

アドレス空間が64ビットでは足りなくなる世界、HPC寄りだと既に割と見据えている感じ
だっていきなり SPARC には Lisp 向け命令があるという噂は実はタグ付きポインタ演算命令があって……みたいなクソ面白い話出てくるんだもんこのサイトこわいよ
おるみんさんがg000001さんのブログ読み始めたら止まらなくなった挙げ句Lispマシンのエミュレータとtarを入手して遊んだりしそうだし、ハマり具合によってはAllegro CLを衝動買いしそう
128-bit になるのってメモリだけじゃなくてバスとかレジスタとか整数演算器とか色々あると思うけど,べつに現代の Intel CPU なんかも AVX512 とかだってあるしな……となると大改革しなくても拡張命令部分だけで十分っぽい気がしてくる
SH-4 の 32-bit 浮動小数点演算ユニット 4 本で 128-bit だ!って広告してた SEGA はともかく。(デュアルコアで bit 詐欺してたのはセガサターンの SH-2 二個で 64-bit!でした……。)
そういえば 128-bit CPU って実際に何が現在存在してるんだろ。実際に製品として広く使われたのは Emotion Engine しか知らないし,あとは RISC-V が 128-bit な ISA あるよなーぐらいしか知らないけど,実際深掘りすると色々出てきそう
の投稿
prime@mstdn.poyo.meこのアカウントは、notestockで公開設定になっていません。
CADR以外にもCONS(CADRの先輩)、NIL(New Implementation of Lisp)、Tなど、昔のLispはそういうネーミングがちらほらある
lesspipe だと less foo.pdf やったときそのマシンに pdftotext とか pdftohtml とかがインストールされてたらそのコマンドの実行結果のほうを less します
思い出した,lesspipe だ。less コマンドでバイナリ喰わせるとマシな出力にするやつ
の投稿
prime@mstdn.poyo.meこのアカウントは、notestockで公開設定になっていません。
どんなバイナリでも less に食わせれば一応は表示するのと,wrapper になっててマジックナンバーによっては objdump したり何らかをしたりしてちょっと見易くしたりする less があったりする
ISA というかニーモニックが Blackfin は面白い気がする。= とか使っちゃうあたり。
MITで作られた由緒正しきLispマシンのひとつにCADRというものがあって、これはマニュアルやエミュレータだけでなく回路図やそれを元にプロセッサ部分をVerilog HDLに書き換えたものすら公開されている
あんまりにニッチなブログ見つけちゃって泣いてる >> インライン・アセンブラ - Blackfin空挺団::Blog http://d.hatena.ne.jp/suikan+blackfin/20060617/1150548540
この前 Renesas RX の ISA を初めてちらと眺めてみたのだけど,あんま面白くなかった(ISA に面白さを求めるな
有名でない有名 ISA/CPU はすごい納得感ある。一方 Blackfin みたいな完全に DSP 向けとかのやつは組込み業界の人じゃない限りマジで知られてないとかありそう
有名でない有名ISA/CPU:MMIX、PDP-11、VAX、Alpha、PA-RISC、RISC-Vより前のバークレーRISC、……
の投稿
prime@mstdn.poyo.meこのアカウントは、notestockで公開設定になっていません。
@babukaru とはいえ glibc でもシステムコールを発行して OS に処理を依頼するところなんかはやっぱり CPU ごとに違うから,そういうところはアセンブリで記述されてたりするけれども……(あってよかった libc
@babukaru 逆に言えば,OS の上で何かするコードを書くぶんには,コンパイラが面倒見てくれる範囲になるので便利
@babukaru ユーザーアプリケーション部分は CPU の特権が要らない命令しか使わないし,そういうのは単純な算術命令だからコンパイラパワーでどうとでもなるのだけど,メモリへのアクセスだとか特権命令(それこそ CPU のモードをカーネルモードに切り替えるだとか)なんかはだいたい,CPU 毎に作法も命令も違うのでね……。
の投稿
prime@mstdn.poyo.meこのアカウントは、notestockで公開設定になっていません。
@babukaru Apple が Newton というモバイルデヴァイスを出したときの初期の Arm は自身で製造までやってそうだけど今は
マジかよ >>
“トランスメタはふたつのx86互換CPUアーキテクチャ、CrusoeとEfficeonを生み出している。これらは低消費電力と発熱特性の良さを武器として、ノートパソコン、ブレードサーバ、タブレットPC、高静粛性のデスクトップパソコンなどに使われたことがある。”
トランスメタ - Wikipedia https://ja.wikipedia.org/wiki/%E3%83%88%E3%83%A9%E3%83%B3%E3%82%B9%E3%83%A1%E3%82%BF
@babukaru そういえばこれ,そもそも Arm は CPU じゃなくて CPU の ISA や回路の設計やらの知的財産しか売らなくて自分自信は CPU を作らない会社です(なので Apple A10 だの Snapdragon 800 だの,色々な会社の Arm SoC があるってわけです)
いろいろなスーパースター人材をバキュームの如く吸い込みながら何も出てこなかった不思議な会社,Transmeta
DEC,今で言う Google みたいな超絶すごい人間が集まってたけど潰れた。Unix が初めて実装された PDP-11 とか TCP/IP が Unix に実装されたとき使われてた VAX とか作ってた会社で,Windows NT を作った David Catler も元々 DEC ですね(彼は今 Xbox 向けのハイパーヴァイザーとか作ってるらしいね
それにCISC、RISCときてVLIWの話をするとなるとItaniumか古いRadeonか、さもなくばマニアックな代物になってしまうので……
この時に AMD64 の命令セット作った人,元々 DEC で Alpha という 1990 年代に最速を誇った CPU 作ってて,AMD64 の直後は Apple で iPhone 4 や iPhone 5 の Arm CPU を作って,その後は AMD に戻って Zen を作ったりしてて,Jim Keller と言うのですが異常か?
Linux も IA-64 のために 2000 年とかに既に EFI 対応コード書いていた……。
ちなみに IA-64 なものはほぼ何も残らなかったけど,IA-64 なマシンに採用された新規のファームウェアは UEFI と改名して他のアーキテクチャに移植されたので現在みんなの PC で動いてます
なので Intel 64 命令は AMD64 命令の後追い(Intel の命令が元ネタなのに……)という不思議さ
一方 AMD はその隙に既存の x86 命令を勝手に 64-bit 拡張して一山当てて儲けた
Intel も x86 の複雑さや歴史的経緯にうんざりしてたので,64-bit の,x86 とまったく互換性のない,しかも VLIW というアーキテクチャで実装した完全新規 CPU を作った上に,Microsoft や HP と組んで新しいファームウェアと業務用マシンを作って Windows の対応までさせたのに,まるで売れないし VLIW はわりと人類に早いという結論になって,廃れたやつです
かるばぶさん IA-64 しらなさそう,IA-64 の歴史すごいおもしろいから調べて
同様の話として,絶対 QEMU なんて C 言語でオブジェクト指向してる魔窟には入らないぞ!つってたのに今は毎日 QEMU のコード眺めて改造してるし,メモリまわり苦手だから Linux mm 絶対避けて生きるぞ!つってたのに mm/memory.c をよく眺める人生になってしまった。
x86_64 なんて歴史的経緯で複雑化した九龍城めいたアーキテクチャ,絶対勉強したくないし asm の勉強しないぞ!って思ってたんだけど結局 x86_64 上でメモリテーブルゴニョったり VMX ゴニョったりするコードばかり眺めるハメになってる
あとはファミコンに使われたモステクノロジーズの 6502 とか,Intel で CPU 作ってた嶋さんがスピンアウトしたザイログで作られた Z80 とか(ゲームボーイで使われたり,未だパチンコに使われたり)
PowerPC 以前の Mac に使われてたモトローラの MC68000 は美しい直交性の高い ISA として根強いファンが居たし,SHARP も MC68000 を使った X68000(X68k,通称ペケロッパ)出してましたね(ペケロッパは筐体デザインが特殊で,そのマンハッタンシェイプに未だファンは多い)
1990 年代は日立製作所(現 Renesas)の SH(SuperH)とかあって,セガのゲーム機とかで採用されましたが,ハイパフォーマンス向けにはちょっと難しくなって,モバイル向けにしても Arm が伸張したりして,結局フィーチャーフォン向けとしてしばらく細々やってたり……。
有名どころ,x86_64,Arm,MIPS 以外だと,今は IBM POWER としてスパコンやメインフレームで使われる PowerPC(2005 年より前の Mac の CPU でした)とか,Sun Microsystems の SPARC とか(富士通がスパコンに使ってて,京コンピューターも SPARC です),そこらへん?
@babukaru 最近,華為が Arm との契約を一切 suspension されたというニュースでざわざわしてたのはこの話が結構重要だからで,Arm の契約止められると Arm を名乗る CPU を作れなくなっちゃうんだよね……。
ちょっと CISC と RISC みたいな話で延々 post しちゃったけど,RISC は英国の Arm も有名だけどスタンフォードの MIPS がほぼ同時期に生まれて,しかも教科書に使われたり当時の『トイ・ストーリー』とかの CG レンダリングに使われたワークステーションに採用したり,いっとき MIPS 天下だった時代があって(PlayStation も Nintendo 64 もそれらのうちのひとつです),この MIPS を作ったスタンフォードの教授とバークレーの教授は一番最近のチューリング賞を受賞してます
@babukaru たとえば C 言語だと main 関数より後の部分はだいたい C だけでなんとかなるけど,C 言語じゃ書き分けられない部分は C の中にアセンブリ埋めるハメになるし,main 関数を実行する前に準備しておきたいものとかは機械語で自分で別に記述して main の前にガッチャンコする必要があるのです(ガッチャンコするときに,どのコードとどのコードをどういう順番で結合するか,ということはリンカスクリプトでプログラマが指定できるので
コンピュータアーキテクチャI http://ocw.kyushu-u.ac.jp/menu/faculty/09/4.html
この講義資料は学部後半の講義だったら飛ばす内容を丁寧に説明しているので詳しくない人にも安心して勧められる
@babukaru コンパイラは与えられた処理を規約に従って翻訳することしかできないので言語規格を越えることはできないからねえ。OS の領分までコンパイラがやるんだったら,コンパイラは常に OS とアプリをセットで生成して,アプリごとに OS が存在することになっちゃう(なんと,そういう考えの OS 設計である libOS や Unikernel という研究もあるのだけど,それはあくまで研究なので
@babukaru ほかにもカーネル内部の memcpy のような関数はアセンブリ命令で実装されるので,x86_64 なら mov 命令だけど Arm なら ldr 命令と str 命令(それぞれ,load と store です)を使うでしょうね,ということで,そこもアーキテクチャごとに違います
@babukaru x86_64 だと CPU のサイクル数を TSC から取得する命令をつかって,それを周波数で割れば,1GHz 以上の周波数の CPU はつまり 1 ナノ秒以下の速度でサイクルを刻んでるので結果としてナノ秒精度が取れるのだけど,ほかにも HPET という高精度タイマがハードウェアで実装されてたりしてて,かなりややこしかったりする。
@babukaru ほかにも,ナノ秒レヴェルの高精度タイマを取得する機能は OS の API に搭載されてて,さらに OS 毎の違いを吸収したライブラリがあるので,たとえば C++ なら std::chrono のクラスのメソッドを呼ぶだけで良いのだけれども,実際はその手法が CPU ごとにやり方も命令も全く違うのでアセンブリなり機械語なりを書かなきゃいけない。
@babukaru さきほどまでの説明はあくまで ISA が一番違う,という説明だったけど,ISA 以外も勿論まったく違うからそうなる,という話ですね。たとえば Intel x86_64 を BIOS から起動すると,歴史的経緯でまず Intel 8086 互換の real mode,つまり 16-bit で起動しちゃって,メモリも 640KB しか使えず,その管理もページング方式ではなくセグメント方式になってます。なので 64-bit のフル機能を使うために,16-bit,32-bit,64-bit とモードを切り替えるややこしい手続きをしつつ,さらにメモリの管理方式の切り替えとセットアップも必要なのです
@babukaru とまあ,CISC と RISC は徐々に融合しつつあるのだけど,歴史的経緯でそれぞれ別の ISA があるし,なんなら ISA それそのものに著作権があるので,Intel が x86 やーめたつって Arm の ISA を採用するわけにもいかんのですよ。
@babukaru じゃあ Arm でいいじゃんみたいになるのだけど,RISC は RISC で,たとえば Arm なら thumb2 命令のように,32-bit Arm は 32-bit で命令長は固定なのに,thumb2 だと 16-bit 命令使える,みたいな組込みなどの産業の要望に答えて容量を減らせる命令セットが出てきたり,そもそも回路と命令が単純で省電力,という話だったのが,Intel ぐらい高性能しようとすると結局複雑な回路,複雑な命令,電力消費増,となって,現代のハイエンドスマートフォンとかの Arm はもうそれは凄いことに。
@babukaru で,自作 PC マニアが言うところの,SandyBridge から CPU の設計があんまり変化してなくて〜みたいなのは,このマイクロアーキテクチャ部分に大胆な改革が起きてない,というような話,というワケ
@babukaru 具体的には,実は Intel CPU は内部的にはもう RISC みたいになってて,レジスタも 64 本とか 128 本とか持ってて,Intel x86_64 の命令を書いても内部でマイクロアーキテクチャ向けの機械語に変換して,レジスタの使いかたも内部の大量のレジスタにいい感じに割り当てながら使ったりしてます。
@babukaru で,しかももっと言えば,実は Intel CPU は ISA と実際の CPU の設計(これを,マイクロアーキテクチャと言います)で分離してて,ISA から見える見掛けの CPU の設計と,実際の中身の設計は全くのベツモノだったりします。
@babukaru たとえば x86_64 は一本一本のレジスタが eax→rax という風に 64-bit 化しただけじゃなくて,r8,r9,... r15 と汎用レジスタが 8 本ぐらい増えてます(あと英字だけじゃなくてレジスタ番号を使う命名も RISC っぽい)
@babukaru RISC はほぼ全ての命令が 1 サイクルで終わる以外にもレジスタ本数がたくさんある(64 本とか)という特徴があって,反面 x86(32-bit)だと eax,ebx,ecx,edx,esi,edi ぐらいしか汎用レジスタがないし,Z80 に到っては 3 本ぐらいしか汎用レジスタがないのだけど
@babukaru とはいえ実は CISC と RISC の差がほぼ無くなっているのが近年の計算機なのだった……。
@babukaru それぞれどういう方針の違いかというと,CISC は 1 命令にかかる CPU のサイクル数(CPU は命令フェッチ,デコード,実行,メモリアクセス,書き戻し,と 1 命令を行なうのに回路を何度もぐるぐるします)が増える傾向にありますがそのかわりチップを微細化して高速化します。反面,RISC は単純な命令を命令パイプラインという形で並列に実行するので,どの命令も 5 サイクルとかで終了して,どの命令同士にも依存関係がなければ,全部の命令が並列して実質 1 サイクルで終わるので高速,といった考え。
@babukaru CISC は基本的に 1 命令で複雑な仕事をこなせます。対して RISC は1 命令はとても簡単な命令で,しかも CISC は命令ごとに命令の長さが違いますが,RISC は全部の命令が固定の長さだったりします。
@babukaru というのも,x86 は CISC(Complex Instruction Set Computer;複雑な命令セットの計算機),Arm は RISC(Reduced Instruction Set Computer;縮小された命令セットの計算機)と,一般的に分類されるのです
@babukaru 緑と青はやっぱり関数のプロローグ/エピローグなので似たようなことしてると思えばよいのだけれども,行数が多いですよね。これは単純なかけ算の関数なのでやってる内容も命令も大差ないのでこれで一概に Arm64 のほうが命令列が長いとは言えないけど,実は x86_64 のほうが命令のバイト数は少なくなる傾向にあります
@babukaru そのあと mov 命令と imul 命令の 2 行で num * num を行なって,eax レジスタにその結果を積んでます。x86_64 の標準の呼び出し規約では eax レジスタに返り値を置くことになってるので,imul(かけ算命令)の結果がそのまま返り値になる。最後の色分けの青っぽいところが関数のエピローグで,pop 命令で保存してた呼出元のスタックのベースポインタを復帰して,ret で呼出元にジャンプするわけです。
@babukaru これが Intel のx86_64。色分けされている最初の緑は関数のプロローグで,関数を呼び出した元のスタックメモリの情報を保存した上で新しいスタックフレームを作成してます。(スタックのベースポインタとスタックのトップを指すポインタはそれぞれ rbp と rsp というレジスタに置かれるので,rbp をスタックに保存した上で,今のスタックのトップの位置をスタックの底である rbp に変更して,さらに edi というレジスタからスタックの上に積んで,これを int num と見做しているわけです)
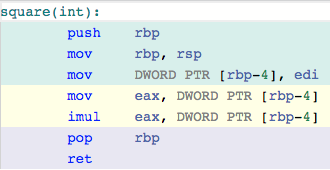
@babukaru たとえばコンパイラが吐く assembly lang を眺められるこの https://godbolt.org サイトで,
```C
int square(int num) {
return num * num;
}
```
という単純なコードをコンパイルすると,
@babukaru architecture=設計なので,設計が違うと,根本的に何もかもが違います……と言っちゃうとそれで話が終わるのでもうちょっと突っ込んだ話をすると,OS にとって arch/ 以下で MD(machine depend)として分離されているコードはたいてい,ISA(Instruction Set Architecture),命令セットアーキテクチャが大きく違いますね。
Linux kernelをUnikernelのライブラリ化する - めもちょー
https://retrage01.hateblo.jp/entry/2019/05/30/232623

愚策!?総務省肝いり「分離プラン」でも携帯料金が改善されない理由(西田 宗千佳) | ブルーバックス | 講談社(1/3)
https://gendai.ismedia.jp/articles/-/64908?media=bb

それシミじゃなくてただのバックライト漏れっぽそう(液晶の仕様上まあ必ずそれっぽいのはあるよね)
@akahana これとかもはや不安になるレヴェルじゃないですか https://fontworks.co.jp/fontsearch/item?TsukuQMinLStd-L&word=%E6%96%87%E5%AD%97%E3%81%8C%E3%81%8A%E3%82%8A%E3%81%AA%E3%81%99%0A%E6%96%B0%E3%81%97%E3%81%84%E3%83%87%E3%82%B6%E3%82%A4%E3%83%B3%E3%81%AE%E4%B8%96%E7%95%8C




