E500 is なに、そんなに良いものなの
 らりお・ザ・何らかの🈗然㊌ソムリエ(@lo48576@mastodon.cardina1.red)の投稿
らりお・ザ・何らかの🈗然㊌ソムリエ(@lo48576@mastodon.cardina1.red)の投稿
Amazon.co.jp: パナソニック カナル型イヤホン ブラック RP-HJE150-K: 家電・カメラ
https://www.amazon.co.jp/dp/B001HXYEYW/
これ

このアカウントは、notestockで公開設定になっていません。
このアカウントは、notestockで公開設定になっていません。
久々に lifetime で苦しんでる
いや効率を無視して clone を躊躇しなければ余裕も余裕なんだが……
テーブルのエントリを書き換えながら再帰的に別エントリを参照 (かつ書き換え) みたいなことをやっていて、まあそこそこつらい
テーブル内だけの話なら Rc<RefCell<T>> でどうにかできなくもないんだけど、ここで enum を match で unwrap してフィールドを読みながら全体を書き換えたりだとか、外部から与えられた T / &mut T と RefMut<T> を同じアルゴリズムに食わせてかつ再帰を避けたりだとか、まあいろいろ余計なことをだな
結果をキャッシュしようとかいう邪念がよくないんだよなぁ
ふたなりは良くて男の娘や TSF は微妙なの、自分でも自分の性癖をよくわかっていないので何もわからん
https://pl.komittee.net/objects/5c0b893d-be61-43f8-a02e-b26611e6b3b4
これはウンコと一緒に出てくる水素ガスと Caddy が扱える h2 をかけた高度なジョーク #適当
人の発言を勝手に高度なジョークに仕立て上げる貴族の遊び

設問じゃなく教え方の方で言うと、(ある程度単純な)仕様を提示して作らせて、動かして適合してるか見て(意図としてはここで失敗してほしい)「ハイ、駄目><><><」って楽しく失敗して、失敗することにより仕様をよく読むみたいな考え方というか習慣というか、設計のしかたというか、そういうの身に付け無いと仕様を読めるように(言語力って意味じゃなく設計に反映させる意味)ならないと思う><
じゃないと言語能力云々以前に、『仕様を設計に反映させるということ』がもやっとしすぎて、重要性を認識できず(役立つことが書いてあると思わず)真面目に読まないと思う><
文章を読んで理解するのも、結局経験値よな。本を読んで「完全に理解した」と思って読み進めたら「何も分からない」になるのも、序盤の文章を読んでどこで区切れば後半の流れになるのかを復習する、みたいな。その上で、説明不足だから誤解するのも当然って逆ギレしても、自分が書くときには気をつけようって思えるかどうかとか。
批判的な物の見方とか邪悪を想定する考え方、どうしても育ちか性格の悪さみたいなのが必要な気がするんだよなぁ。或いはある種の冷酷さとか。
先天的な素質だと思いたくはないんだけど
たぶん思考と行動を区別できない人々が一定数いて、「悪いことを考えること自体が悪いこと」とか「悪いことを思いつくのは悪い人」みたいな価値観を持っていて、「善良な思考」しかできないように自分を縛ってたりするのではないかなと
ていうか、プログラミングの世界に慣れてない人々、失敗を恐れまくるの、「文化の違い!><;」って感じ><
コンパイルエラーを出すのが忌避すべきだと考えるのも同じようなやつか
そういう人たち、邪悪な「仮定」で物事を考えられないのよね。思想と行動が区別できなくて、仮定と事実も分けて考えられないから。
twitter とかで「もし〇〇なら✕✕」に対して「〇〇なんですか!ひどいですね!」みたいな日本語読めてなさそうな吹き上がり方してる人はたぶんそのタイプ
こういうの、「失敗を恐れない」とかそれ以前の問題で、「失敗してもマズくない状況や考えても実行されない概念などの存在を認識できない」という思考フレームワークの欠陥なんじゃないかと思っていて、そういう人々に「コンパイルエラーは怖くないよ」とか「人を疑うことは大事だよ」と説明しても通じるものではないだろうと

このアカウントは、notestockで公開設定になっていません。
URL 引用と WebMention という救いの希望が Mastodon では絶たれてしまったので打つ手なし!
HTML の blockquote にも DocBook の blockquote にも全く満足できてないんだけど、メタデータ表現が貧弱すぎない?
blockquote
https://tdg.docbook.org/tdg/5.2/blockquote.html
まあ DocBook はとりあえず全部 info に突っ込んで、あとでテキトーに別の語彙からメタデータの名前を拝借してきて RDF で表現するとかできそうだけど……
ブロック引用、どう考えてもいろいろ追加のメタデータが付くはずなんだけど、既存のフォーマットがその辺り弱すぎて話にならない
たとえば軽く探すだけでも
* 部分的な省略 (snip, cont)
* 引用者による強調
* 引用者による註
* 発言の日時または文書公開・改定日時
* ソース文書の参照日
あたりがあるんだけど、この辺りをちゃんと機械可読にしたフォーマット見たことない (TeX 系は頑張れば少しいけそう?)

面白いアニメがあると3ヶ月寿命が延びる.3ヶ月更新なので実質let's Encryptだし,我々は実質サーバだった(飛躍
文書スキーマ自作一択なんだよなぁ……ブログは一度頑張って DocBook 5 + 独自拡張に落としたけど、やっぱり厳しいわ

このアカウントは、notestockで公開設定になっていません。
Web Annotation Data Model
https://www.w3.org/TR/annotation-model/
REC じゃん、知らなかった……
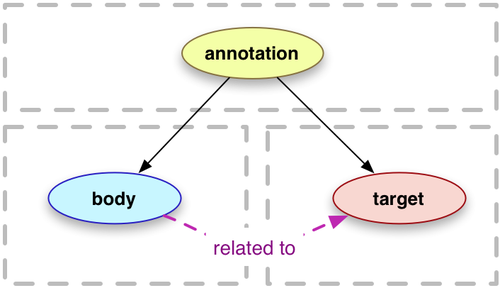
> An annotation is considered to be a set of connected resources, typically including a body and target, and conveys that the body is related to the target.
ふむふむ
最初に「JSON 表現を提供するよ」とあってその後いかにも RDF っぽい図が出てきて、ほっこりしたあと顔が真っ青になったよね
(文脈: JSON-LD ライブラリを静的型付き言語で実装しようとして苦しんだことがある)
ババーン
> The examples throughout the document are serialized as [JSON-LD] using the Context given in Appendix A of the Annotation Vocabulary [annotation-vocab], which is the preferred serialization format.

このアカウントは、notestockで公開設定になっていません。
おっいいじゃん
↓
JSON 表現ね、はいはい
↓
ふむ、いかにも W3C が好きそうな RDF 的グラフじゃん (ほっこり)
↓
まてよ、これはまさか……
↓
JSON-LD \コンニチハ/
▂▅▇█▓▒░(’ω’)░▒▓█▇▅▂うわああああ

このアカウントは、notestockで公開設定になっていません。
TEI 、興味はあったんですが、ユースケースが「既存のメタデータ皆無の非機械可読文書をうまいことメタデータで装飾する」みたいなのが多いのと、「モジュール的に拡張を持ってきてプロセッサに能力を追加する」みたいなのがあった気がして Java っぽいなぁと思ったので、あまりしっかり勉強していない
(新規の文書を綺麗に書くのにも使えるということは知っている)
DITA とかもそうなんですが、 OOP 的な「継承」のモデルをスキーマに持ち込むの、ユーザとしてはそこそこ綺麗な抽象化ではあるんだけど、処理系の実装言語のパラダイムを著しく制限するのであまり好きではないです

JSON-LD、一握りの天才のためのフォーマットという感じがして非常に心温まる、11000まで回る
https://mstdn.maud.io/@kb10uy/103037909369584800
何をおっしゃるか、 JSON-LD は「RDF は利用者のことを考えていない! 我々は既存のアプリケーションが適合しやすいよう実用性の高い規格を作るぞ!」となって出来上がった世界の味方ですぞ (白目)
プロジェクトを開いたら :w というファイルが見付かって笑顔になった
小学生時代から宿題を後回しにしてパソコンして、親に宿題したと嘘を付いたり、学校でやったけど持ってくるの忘れたと言って翌日もってこいと言われて結局だめだったり、それでなんとなくいい点数取れてたりすると勉強する習慣が付かなくて、トライアンドエラーはどこでも一緒なんだろうけど、なんか家の勉強机に座って勉強するのが苦手になってしまった。そもそも勉強ってなんだ、問題を解いて答え合わせをして、間違いだったところをやり直そうにも答え見ちゃったし、みたいなことでなんも分からないまま生きてきてしまった。
失敗して怒られるのが嫌。それは確かにそう。失敗しても怒られない試行の段階で失敗しまくっても怒られないし、結果的に本番で怒られる可能性も減るんだけど、そこまで試行を重ねるほどの時間もないんだろうなぁ。面倒なことを後回しにするとか、現実逃避に走ってしまうとか、優先順位が付けられないとか、色々理由はあるんだろうけど。辿っていくと、たぶん全然遠いところに行き着いちゃったり、回り回って結局どこから改善したら良いんだみたいなことになりそうな予感。
小中学校で何もしなくてもなんとなく良い結果が取れてしまって高校まで行くと嫌いな科目を捨てる程度の知恵が付いてしまうので最終的に楽しいことだけやって予習復習の習慣がついぞつかないまま「授業」という概念と接することがなくなってしまった、人生

このアカウントは、notestockで公開設定になっていません。
コミットメッセージを日本語で書くことがまずないので l 混入はマッドドンが多い

このアカウントは、notestockで公開設定になっていません。

このアカウントは、notestockで公開設定になっていません。

プログラミング、グラフで作ったものを切り開いて木構造とリンクに展開する作業なので、どこに切れ目を入れるかでセンスが問われてしまう
中学の時に、なんか100点とか90点台が普通に取れていたので、「本番に強いとか」「実は実力がある」とか勘違いして、高校で「実力テストは実力で受けないと意味が無い」とか言って大爆死してそのまま落ちこぼれ太郎と申します。
> 高校で「実力テストは実力で受けないと意味が無い」とか言って
これわかりすぎて笑顔になった、オタクみんな同じ屁理屈言ってたんじゃないかと思ってしまうくらい
定期試験、マジで「今どこまでできるかわかる」程度のものでしかなかった (勉強したいというモチベーションに繋がらなかった)
そもそも予習復習してないから授業聞いてるだけで †完全に理解† するしかないし
大学とかは得意目の科目がかなり多くなるのでなんだかんだでなんとかなってしまう (ほんまか)
専門学校の時は、勝手に進めて授業でやってないことを盛り込んでも評価してもらえたので、あいた時間は他に趣味のコードを書いたりして、あのときが本当に一番勉強していたと思う。
学校での勉強のしかたなんもわからん落ちこぼれなので独学になったし独学の方法も自分で考えた><
私もポヨグヤミン (特に手を動かす方) に関してはほとんど独学バッファが空にならなかった
でも理論全振りみたいなやつはやっぱり授業受けてよかったし、パワがほしいならやりたいことやるしかねえよ

大学を出てしばらく経ってようやく「勉強する方法」ってのを少しだけ理解したんだよな。一体今まで何やってきたんだろうな。僕は。
https://blog.dereferenced.org/pleroma-litepub-activitypub-and-json-ld
JSON-LDの利点はデータ豊穣化(data enrichment)
データ豊穣化が有用なのは広告と諜報 🤔

JSON-LD 、「既存のデータの構造を保ったまま外部由来の意味付け (スキーマ) を関連づける」と「既存のスキーマに別スキーマ由来のデータを追加する」などが主な機能なので、前提からして「任意の外部定義の追加メタデータが来る状況で JSON-LD が活きてくる」というのはあります
ActivityPub がそうかというと、まあ少なくとも現状のユースケースではあまりそうでない。
あともうひとつ、 ActivityPub は処理系が JSON-LD 非対応で良いようになっていて、 ActivityPub の語彙については特定のデータ構造が強制されるので、あまり JSON-LD みがない
現状で使われているアプリケーションの ActivityPub に入ってる追加データ、たとえば Mastodon だと
https://w3id.org/security/v1
とか
http://joinmastodon.org/ns#
とか
http://schema.org#
くらいなので、まあ確かに有用ではあるけどうーむ? という感じ。
joinmastodon を除けば、頑張れば ActivityPub 仕様に組込むこともありえたかなと
もちろんこれから様々なメタデータを付けるアプリケーションが増えるかもしれないし、そうなってくるとかつての HTML のように処理系独自拡張だらけで相互運用性がなくなるような事態を回避できる JSON-LD はかなり素敵ではあると思う
(ぶっちゃけセマンティックウェブは概念の名寄せをしたいんだし、概念が名寄せされるのであれば個人も名寄せできるのは当然なのでは。その主な用途が広告と諜報ってのは悲しいが……)
「処理系独自拡張だらけで相互運用性がなくなる」問題、名前空間で分ける程度では解決できないのでは……(まじめにJSON-LDのコンテキストを処理すればどうにかなるかもしれないが、結局真面目に処理するひとがいない問題)
https://pleroma.ryusei.dev/objects/b74940d2-35c6-4c74-b42d-08f335ec0297
まさにこれこそ XML の namespace 的な仕組みでなく JSON-LD が必要な理由で、 JSON-LD は「特定スキーマで定義された構造を、スキーマでの名前とは全く別の名前や構造と対応付ける」ができるので強い (そして処理系がつらい)

このアカウントは、notestockで公開設定になっていません。
結局今のHTMLは名前空間決め打ちでSVGとか取り込んでいるわけだけし、名前空間は雑でもなんとかなるっちゃなるのか?(しかし決め打ちは中央集権的すぎるか?)
XML 文書におけるスキーマは「定義された字句的構造を持つデータを組み合わせる」技術で、 JSON-LD におけるスキーマ (正確には context) は「外部で定義された抽象同士のグラフ構造を、スキーマにおける定義の字句的構造とは別の字句的構造を持つデータと関連付ける」という技術なので、割と違うものと捉えている
XML のそれは「別形式データの埋め込みのサポート」で、 JSON-LD のそれは「データ構造からデータ構造への写像の定義」という感じ
このアカウントは、notestockで公開設定になっていません。

jpユーザーのお気持ちに配慮して、事実上 pawooだけ遮断→pawoo以外全部遮断 に転換するまさかの展開
字句的な構造をスキーマでなくアプリケーションでのネイティブ処理に都合の良いようにできる (そもそも既存アプリケーションのそれをそのまま使ってスキーマ定義のデータ構造への写像を後付けにできる) というのが売りだったわけで、まあ確かに便利で有用だろうとは思う (ただし処理系がつらい)

このアカウントは、notestockで公開設定になっていません。
個人用インスタンスにしてコミュニティ運営とかいう本質的でない難題から解放されよう
https://pleroma.ryusei.dev/notice/9oNDwdOzO9RDR8Q4iu
セマンティクスがツリーかグラフかで、どれだけ変わるのか 🤔

schema.org自身がすでに文字列またはThingがくるプロパティみたいなのがたくさんあり、相互変換もなにもなさそう
XML のような「埋め込み」だと、「あるスキーマから見て別スキーマ由来のデータの中身を知ることが困難」という問題があって、 JSON-LD は埋め込みではなく語彙への写像を提供するという手法によってこれを解決している
つまり知らないスキーマで知っている語彙が使われていたとき、処理系がフィールドやオブジェクトをスキーマ上のデータに限らず語彙そのものへ写そうとするので、知らないスキーマによって知っている語彙へマップされているフィールドを、そうであると認識することができる
JSON-LDはまあオブジェクトグラフを交換しつつ、簡易的に処理することもできる枠組みとしてはよいのだけど、ただ外部のグラフを取り込むことを考えると、表現から独立してセマンティックに処理できるクエリ言語が欲しくなる
ただ……SPARQLは……あんまり使いたくない……
でも結局 JSON-LD も根底にあるデータモデルは RDF のグラフなので、こればかりはどうしようもない気がしている (つらい)
たとえば JSON-LD context でフィールドを逆向き property にマップすることができて、たとえば
"foo": "bar" を subject "bar" と property https://example.com/#prop と object "foo" の関係であるというように context を作ることができるんだけど、これネイティブに扱うのめっちゃ面倒そう
木構造の限界という感じがするし、だからこそ抽象的なデータ構造のグラフの素朴な反映ではなく、アプリケーションに都合の良いネイティブ形式との相互変換を最初から前提にした形式になっているのだろうなと
まあ言うて肝心の JSON-LD Framing は JSON-LD 1.0 規格に入らなかったので 1.1 に向けて策定中なんだけどなwww
つまり「JSON-LD データをアプリケーションにとって都合の良い字句的構造に変換するアルゴリズム」が未だ Working Draft なので規格としては片手落ち状態
JSON-LD 1.1 Framing
https://www.w3.org/TR/json-ld11-framing/
JSON-LDの変換、汎用的な仕組みだとパフォーマンスがでないから、ハードコーディングするわってなりそう
それかRDBみたいにクエリオプティマイザを備えて、インデックス張って性能改善するみたいなテクニックか要りそう
まあ ActivityPub が JSON-LD として読めるよと言いつつ構造を固定したのは実際それが理由でしょうね……
MastodonもPleromaもデータはPostgreSQLに突っ込んでるんだよなー……
https://pleroma.ryusei.dev/objects/df2a772c-8b6b-4d81-b896-b904a022f6d0
たぶんこれ自体は (理想的には) 正しいやり方で、我々は JSON-LD データの **解釈可能な部分は** アプリケーションネイティブのデータ構造に読み込んだ上で扱うことを推奨されている
@mandel59 リンクは「データに名前を付ける」ことと「それぞれが名前付きデータ自分のわかる形に変形して再解釈する」ことで実現できるのかなと思っていて、この「変形して再解釈」の部分を JSON-LD が発明したことによって統一的な構文の共有が不要になるのだと考えています。
それで、処理系 (受信者) による変形と再解釈が当然行われるものと考えるなら、アプリケーションが敢えて自分に使いづらい形でデータを保持する必要はなさそうかなと。
たとえば、MastodonのデータをエクスポートしてPleromaに取り込む、みたいなことはできるか? RDBレベルではスキーマが違うから、変換しないといけない。
この辺り、「アプリケーションが持っているすべての情報がオープンに開示されているわけではない」というアレがあるのでそこはまた別に考えるとしても、理想的には ActivityPub の json で DB をダンプしたりインポートできるようにするのが良いのでしょうね……
git add、コミット予定に追加すると思うと、コンフリクトの修正後や、新規ファイル追加や、更新したファイルの時に指定する意味が分かりやすいと思う。そう言うわたしも、すぐ更新分だけ指定して直接commitしようとして、ファイルが抜けたりしてresetしたり、別でcommitしてrebaseで整えたり、後始末でなんとかしていることが多い。
git add 、普通に “staging” だと説明されるのでそれでわかるでしょみたいな気持ちがあるけど、日本語にうまく訳すのが難しそうなので誰も端的に説明できていないみたいな雰囲気を感じている
神経質なので日頃 git add -p で差分を確認しながらステージすることが多いんだけど、 add -p は新規に生えてきたファイルを追加してくれないので悲しい
HTML の嫌いなところなんですが、 <q> で括った文章の鍵括弧とかクォーテーションマークが表示上は装飾なのでテキストとして選択できないのがとても嫌です
落ちかけのサーバにアクセスしてステータスコードを眺める fediverse 住民、それ DDoS だし邪悪すぎて爆笑してるよ私は

このアカウントは、notestockで公開設定になっていません。
このアカウントは、notestockで公開設定になっていません。
むしろスケールさせないといけない大規模サーバの存在こそが癌でしょ (原理主義者並感)
個人でしか利用しないサーバから接続するインスタンス数とデータ量なんて高が知れてるでしょ、人を無闇に集める大規模サーバが勝手に自重で苦しんでるだけにしか見えない
そもそも鯖とユーザを分散することで負荷も分散してるんだから、ユーザ集めたら負荷も集まるのは当然すぎるというか
全体的には当然負荷分散によるオーバーヘッドもあるだろうけど、個々の鯖としての負荷は分散で軽くなるはずやで
このアカウントは、notestockで公開設定になっていません。
分散でコストが増すのは「ネットワーク全体としての負荷」であって、サーバ個々の負荷は分散すればするほど落ちる、当然よ
https://pleroma.ryusei.dev/notice/9oNIGwknY46p3zYsjY
プレーンテキストへのフォールバックはrubyだったら対応しているけど、一般に根深い問題
citeタグとか、英語はイタリックにするだろうけど日本語は(書名は)二重鉤括弧『』で括るだろうし
ruby の rp タグみたいなのがあるべきだという気持ちもあり、一方で毎回 qp タグみたいなのを指定するような冗長で煩雑な機構を人々が使いたがるはずもなさそうという気持ちもあると
いつもの話題的に言うと、いわゆる『セレブ』の人は個人鯖でもわりと重くなるんでは感><
(例えばリーナスがマストドン初めて個人鯖で(キレイに聖人のように)キレまくってたら、読みたい人多くてかなりの負荷になるんでは?><)
でも AP での配信は基本的に polling ではなく push なので、配送者の都合の良いようにスケジューリングできるはずなので、そこは実装次第みたいなところありそう (既存実装がマトモとは言ってない)
@mandel59 クォーテーションマークを q の中に入れるか外に入れるかとか、 CSS でマークを無効化しとかないとマークが二重になるとか、ワークアラウンドまでも微妙なので正直 q タグ使いたくない気持ちでいっぱいです……
b とか i とかは私はあまり使っていなくて span + class 属性 + CSS みたいな感じでそれっぽく拡張してやっていきしていたので、実はそんなにマイグレーションに苦労するイメージは持ってませんでした (たしかに一般の文書はつらそう)
人間にテキストをマークアップさせるの、自然言語処理はつらい以上の理由はなさそう(実際つらいけど、その労力をオーサーに転嫁してもな……)
メタデータなど、解析からの自動生成されると、それが本当に著者の意図した情報なのかわからないまま読むことになって正直嫌です
自然言語のマークアップはそもそも難しい問題なのでオーサーが対応できなくてもしょうがないし、自然言語処理で抽出すればいいのかなって思う
レシートはPOSで機械可読な形で処理してるのに印字したものをOCRで取り込むのはやばいのでできればやめたい
 の投稿
Yohei_Zuho@mstdn.y-zu.org
の投稿
Yohei_Zuho@mstdn.y-zu.org
このアカウントは、notestockで公開設定になっていません。

このアカウントは、notestockで公開設定になっていません。

このアカウントは、notestockで公開設定になっていません。
Zoreto あきらめて flatpak 使ってる (楽)
Zotero—Linux Apps on Flathub
https://flathub.org/apps/details/org.zotero.Zotero
flatpak というのは Docker の GUI アプリケーション版みたいなもので、簡単に言うと OS やライブラリのイメージの上にアプリケーションを乗せたりすることで、環境の隔離とかデータディレクトリの配置とかライブラリのバージョン合わせなどをできるよというコンテナみたいなものです
Flatpak—the future of application distribution
https://flatpak.org/
いい感じの有名な OSS の GUI アプリはだいたいあります (gimp とか blender とか inkscape とかいろいろ)

このアカウントは、notestockで公開設定になっていません。
 の投稿
akkiesoft@h.kokuda.org
の投稿
akkiesoft@h.kokuda.org
このアカウントは、notestockで公開設定になっていません。
まだ終わっていないリクナビ問題 カギ握る「クッキー」:朝日新聞デジタル
https://www.asahi.com/articles/ASMBL6TC9MBLULFA048.html

A, B, .... : FromRequest というハンドラーの定義が生えてるから引数で勝手に判定してくれるよ
こういう感じのマクロがちょくちょく生えてる
https://docs.rs/actix-web/1.0.8/src/actix_web/extract.rs.html#253
std の tuple や array 系の trait 実装も基本的にこんな感じよね。 const generics でこれが綺麗に書けるようになることが期待されているので要注目よ
いや待って、 array は const generics でどうにかできるけと tuple はまた別の話かもしれない (知らない)
NHK、N国党首を提訴=受信料支払い求め(時事通信) - Yahoo!ニュース
https://headlines.yahoo.co.jp/hl?a=20191028-00000069-jij-bus_all
秀逸なコント (?)
このアカウントは、notestockで公開設定になっていません。

このアカウントは、notestockで公開設定になっていません。

このアカウントは、notestockで公開設定になっていません。
このアカウントは、notestockで公開設定になっていません。

このアカウントは、notestockで公開設定になっていません。
ゴイアニア被曝事故 - Wikipedia
https://ja.wikipedia.org/wiki/%E3%82%B4%E3%82%A4%E3%82%A2%E3%83%8B%E3%82%A2%E8%A2%AB%E6%9B%9D%E4%BA%8B%E6%95%85

天女の嫁入り | アルファポリス - 電網浮遊都市 -
https://www.alphapolis.co.jp/manga/official/155000292

このアカウントは、notestockで公開設定になっていません。
「余計なこと」を「お節介」と言い換えると実にいいことをしている気分になれるんですね、勉強になる