活動をFediverseに移していきたいけど、twitterのフォロー関係も惜しい気がするんだ

活動をFediverseに移していきたいけど、twitterのフォロー関係も惜しい気がするんだ

批判的な物の見方とか邪悪を想定する考え方、どうしても育ちか性格の悪さみたいなのが必要な気がするんだよなぁ。或いはある種の冷酷さとか。
先天的な素質だと思いたくはないんだけど
たぶん思考と行動を区別できない人々が一定数いて、「悪いことを考えること自体が悪いこと」とか「悪いことを思いつくのは悪い人」みたいな価値観を持っていて、「善良な思考」しかできないように自分を縛ってたりするのではないかなと

ていうか、プログラミングの世界に慣れてない人々、失敗を恐れまくるの、「文化の違い!><;」って感じ><
コンパイルエラーを出すのが忌避すべきだと考えるのも同じようなやつか
そういう人たち、邪悪な「仮定」で物事を考えられないのよね。思想と行動が区別できなくて、仮定と事実も分けて考えられないから。
twitter とかで「もし〇〇なら✕✕」に対して「〇〇なんですか!ひどいですね!」みたいな日本語読めてなさそうな吹き上がり方してる人はたぶんそのタイプ
こういうの、「失敗を恐れない」とかそれ以前の問題で、「失敗してもマズくない状況や考えても実行されない概念などの存在を認識できない」という思考フレームワークの欠陥なんじゃないかと思っていて、そういう人々に「コンパイルエラーは怖くないよ」とか「人を疑うことは大事だよ」と説明しても通じるものではないだろうと

このアカウントは、notestockで公開設定になっていません。
URL 引用と WebMention という救いの希望が Mastodon では絶たれてしまったので打つ手なし!
ブロック引用、どう考えてもいろいろ追加のメタデータが付くはずなんだけど、既存のフォーマットがその辺り弱すぎて話にならない
たとえば軽く探すだけでも
* 部分的な省略 (snip, cont)
* 引用者による強調
* 引用者による註
* 発言の日時または文書公開・改定日時
* ソース文書の参照日
あたりがあるんだけど、この辺りをちゃんと機械可読にしたフォーマット見たことない (TeX 系は頑張れば少しいけそう?)
Web Annotation Data Model
https://www.w3.org/TR/annotation-model/
REC じゃん、知らなかった……
モバイル版Chromeの下に引っ張ってリロード、SPAアプリケーションと相性悪くない?
最初に「JSON 表現を提供するよ」とあってその後いかにも RDF っぽい図が出てきて、ほっこりしたあと顔が真っ青になったよね
(文脈: JSON-LD ライブラリを静的型付き言語で実装しようとして苦しんだことがある)
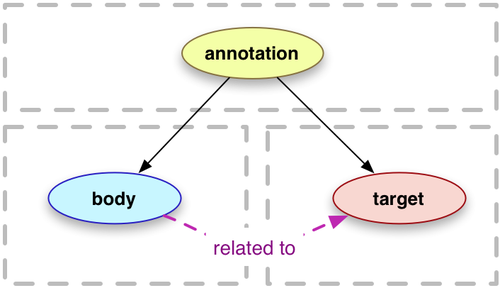
ババーン
> The examples throughout the document are serialized as [JSON-LD] using the Context given in Appendix A of the Annotation Vocabulary [annotation-vocab], which is the preferred serialization format.

このアカウントは、notestockで公開設定になっていません。

このアカウントは、notestockで公開設定になっていません。
このアカウントは、notestockで公開設定になっていません。

このアカウントは、notestockで公開設定になっていません。
DITA とかもそうなんですが、 OOP 的な「継承」のモデルをスキーマに持ち込むの、ユーザとしてはそこそこ綺麗な抽象化ではあるんだけど、処理系の実装言語のパラダイムを著しく制限するのであまり好きではないです
UXデザインもそうで、基本的にすべてアンドゥ出来なければならないし、どうしてもどうしてもアンドゥ出来るように作る事が不可能な場面は、特に後戻りできないことを強く気づかせなければならないし、その場面でもボケっと操作した場合にも安全側の動作になるように作らなければならない><
そういうの普段から頭の片隅に入れておかないと駄目かも><
現在主流のITの文化であるUNIX文化はそうなってない><
(参考文献: 『誰のためのデザイン?』その他のD.A.ノーマンが書いたいくつかの文献)

このアカウントは、notestockで公開設定になっていません。
投票、やさしいにほんごだと「いれふだ」になってる
入札の訓読みだろうけど、日本語の語順にするなら「ふだいれ」じゃない?
このアカウントは、notestockで公開設定になっていません。
プログラミング、グラフで作ったものを切り開いて木構造とリンクに展開する作業なので、どこに切れ目を入れるかでセンスが問われてしまう
入札という行為は「ふだいれ」が自然で、「いれふだ」は入札に使う札を指すように感じるなあ……
専門学校の時は、勝手に進めて授業でやってないことを盛り込んでも評価してもらえたので、あいた時間は他に趣味のコードを書いたりして、あのときが本当に一番勉強していたと思う。
学校での勉強のしかたなんもわからん落ちこぼれなので独学になったし独学の方法も自分で考えた><
でも理論全振りみたいなやつはやっぱり授業受けてよかったし、パワがほしいならやりたいことやるしかねえよ
別に金を回すのはコンピュータ関係じゃなくてもいいんで、金さえ回ればあとは自由にするのがよい

大学を出てしばらく経ってようやく「勉強する方法」ってのを少しだけ理解したんだよな。一体今まで何やってきたんだろうな。僕は。

JSON-LD、一握りの天才のためのフォーマットという感じがして非常に心温まる、11000まで回る
https://blog.dereferenced.org/pleroma-litepub-activitypub-and-json-ld
JSON-LDの利点はデータ豊穣化(data enrichment)
データ豊穣化が有用なのは広告と諜報 🤔

JSON-LD 、「既存のデータの構造を保ったまま外部由来の意味付け (スキーマ) を関連づける」と「既存のスキーマに別スキーマ由来のデータを追加する」などが主な機能なので、前提からして「任意の外部定義の追加メタデータが来る状況で JSON-LD が活きてくる」というのはあります
(ぶっちゃけセマンティックウェブは概念の名寄せをしたいんだし、概念が名寄せされるのであれば個人も名寄せできるのは当然なのでは。その主な用途が広告と諜報ってのは悲しいが……)
(極論人工知能がもてはやされているのは、それで市場がスパイできるからってのはありそう)
ActivityPub がそうかというと、まあ少なくとも現状のユースケースではあまりそうでない。
あともうひとつ、 ActivityPub は処理系が JSON-LD 非対応で良いようになっていて、 ActivityPub の語彙については特定のデータ構造が強制されるので、あまり JSON-LD みがない
もちろんこれから様々なメタデータを付けるアプリケーションが増えるかもしれないし、そうなってくるとかつての HTML のように処理系独自拡張だらけで相互運用性がなくなるような事態を回避できる JSON-LD はかなり素敵ではあると思う
「処理系独自拡張だらけで相互運用性がなくなる」問題、名前空間で分ける程度では解決できないのでは……(まじめにJSON-LDのコンテキストを処理すればどうにかなるかもしれないが、結局真面目に処理するひとがいない問題)
いやまあ名前が衝突しないようにするのは接頭辞使えば難しくないし、JSON-LDのおかげで体系的にできるってのはあるかな
結局今のHTMLは名前空間決め打ちでSVGとか取り込んでいるわけだけし、名前空間は雑でもなんとかなるっちゃなるのか?(しかし決め打ちは中央集権的すぎるか?)
相互運用性持たせるLitePubみたいな枠組みはあるけど、それとは独立して独自拡張を試すことはできるし、良さげだったらそれを標準化してもらう、みたいなフローがまあいいのかな
XML 文書におけるスキーマは「定義された字句的構造を持つデータを組み合わせる」技術で、 JSON-LD におけるスキーマ (正確には context) は「外部で定義された抽象同士のグラフ構造を、スキーマにおける定義の字句的構造とは別の字句的構造を持つデータと関連付ける」という技術なので、割と違うものと捉えている
https://pleroma.ryusei.dev/notice/9oNDwdOzO9RDR8Q4iu
セマンティクスがツリーかグラフかで、どれだけ変わるのか 🤔

schema.org自身がすでに文字列またはThingがくるプロパティみたいなのがたくさんあり、相互変換もなにもなさそう
それはschema.orgが悪いのかもしれないし、もともとかっちり型を決めたところで、一般オーサーが型をちゃんとしてメタデータ作成できないだろってのはありそう……
JSON-LDはまあオブジェクトグラフを交換しつつ、簡易的に処理することもできる枠組みとしてはよいのだけど、ただ外部のグラフを取り込むことを考えると、表現から独立してセマンティックに処理できるクエリ言語が欲しくなる
ただ……SPARQLは……あんまり使いたくない……
まあ言うて肝心の JSON-LD Framing は JSON-LD 1.0 規格に入らなかったので 1.1 に向けて策定中なんだけどなwww
JSON-LDの変換、汎用的な仕組みだとパフォーマンスがでないから、ハードコーディングするわってなりそう
それかRDBみたいにクエリオプティマイザを備えて、インデックス張って性能改善するみたいなテクニックか要りそう
MastodonもPleromaもデータはPostgreSQLに突っ込んでるんだよなー……
@lo48576 誰にとっての理想なんでしょう? アプリケーションが抱えているデータがアプリケーション特有の形で格納する必要があるとなると、オープンリンクトデータという考えは実現が難しいのでは?
たとえば、MastodonのデータをエクスポートしてPleromaに取り込む、みたいなことはできるか? RDBレベルではスキーマが違うから、変換しないといけない。
git add 、普通に “staging” だと説明されるのでそれでわかるでしょみたいな気持ちがあるけど、日本語にうまく訳すのが難しそうなので誰も端的に説明できていないみたいな雰囲気を感じている

このアカウントは、notestockで公開設定になっていません。
HTML の嫌いなところなんですが、 <q> で括った文章の鍵括弧とかクォーテーションマークが表示上は装飾なのでテキストとして選択できないのがとても嫌です
https://pleroma.ryusei.dev/notice/9oNIGwknY46p3zYsjY
プレーンテキストへのフォールバックはrubyだったら対応しているけど、一般に根深い問題
citeタグとか、英語はイタリックにするだろうけど日本語は(書名は)二重鉤括弧『』で括るだろうし
個人でしか利用しないサーバから接続するインスタンス数とデータ量なんて高が知れてるでしょ、人を無闇に集める大規模サーバが勝手に自重で苦しんでるだけにしか見えない
むしろスケールさせないといけない大規模サーバの存在こそが癌でしょ (原理主義者並感)
@lo48576 それ以前にプレーンテキストのクオーテーションマークで十分なのでは? とか、iとかbを機械的にemとstrongにしても全然セマンティックになってないよね? とかある
人間にテキストをマークアップさせるの、自然言語処理はつらい以上の理由はなさそう(実際つらいけど、その労力をオーサーに転嫁してもな……)
自然言語のマークアップはそもそも難しい問題なのでオーサーが対応できなくてもしょうがないし、自然言語処理で抽出すればいいのかなって思う
レシートはPOSで機械可読な形で処理してるのに印字したものをOCRで取り込むのはやばいのでできればやめたい

これ見て甘味処初音を思い出した
外国人旅行者「日本で緑茶が飲みたいのにカフェにない」PET茶を買うしかない現状に様々な意見集まる「気軽な茶屋あるといい」「デパ地下にある」 - Togetter
https://togetter.com/li/1419711
Flatpak—the future of application distribution
https://flatpak.org/
いい感じの有名な OSS の GUI アプリはだいたいあります (gimp とか blender とか inkscape とかいろいろ)

flatpak というのは Docker の GUI アプリケーション版みたいなもので、簡単に言うと OS やライブラリのイメージの上にアプリケーションを乗せたりすることで、環境の隔離とかデータディレクトリの配置とかライブラリのバージョン合わせなどをできるよというコンテナみたいなものです
https://pleroma.ryusei.dev/notice/9oNN088MU4PfCpNrYu
snapと競合するやつだっけ

dsno「国内の個人運営と思われるインスタンスからのアクセスを遮断する」
https://mstdn.jp/users/dsno/statuses/103038133158385043
Mastodon(非公式)「jpが個人サーバーを一律遮断する」
https://mstdn.jp/@mastodon/103038197617923077

まだ終わっていないリクナビ問題 カギ握る「クッキー」:朝日新聞デジタル
https://www.asahi.com/articles/ASMBL6TC9MBLULFA048.html

いつもの話題的に言うと、いわゆる『セレブ』の人は個人鯖でもわりと重くなるんでは感><
(例えばリーナスがマストドン初めて個人鯖で(キレイに聖人のように)キレまくってたら、読みたい人多くてかなりの負荷になるんでは?><)
でも AP での配信は基本的に polling ではなく push なので、配送者の都合の良いようにスケジューリングできるはずなので、そこは実装次第みたいなところありそう (既存実装がマトモとは言ってない)
フェデレーションはプッシュだからそれでいいけどWebフロントエンドは閉じるかCDN挟まないとつらそう
自己診断するのは危険そうというか、不安を感じているならやめておいたほうがいいきがしてきた……



