おはよも 
 白湯さゆぬ(@sayunu@mofu.kemo.no)の投稿
白湯さゆぬ(@sayunu@mofu.kemo.no)の投稿 言葉と文字とヨッシーアイランドが好き。たまごっちやここたまのアニメを見ます。たまに絵を描きます。フォントを作ったりします。2023 年 1 月から https://mofu.kemo.no の副管理人です(いきなり権限を付与されたけど受け入れました)。
ソーシャルメディアの中では ここが常駐場所です。大体全ての活動をここに集約します。ActivityPub 対応サーバーからリモートフォローしてください。なおフォロー外からの非公開返信は受け取らない設定にしてます。
日本語の研究で博士号を持ってるけど、離れて長いし、自信ない。キーボードは新 JIS‐配列(JIS X 6004)微改変版です。今のプロフィール画像は『スーパーマリオブラザーズワンダー』の一般ポプリンの絵です(二次創作)。
全ての #絵 を見るにはこちら :
https://mofu.kemo.no/@sayunu/tagged/%E7%B5%B5
ここたまに興味がある人は、ここたまアンテナ(@cocotama_antenna)をフォローしてね。
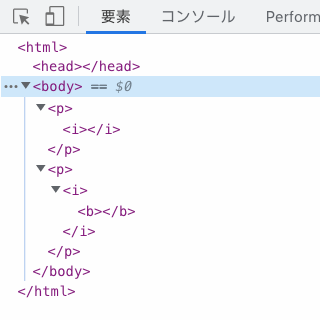
太古の既存ウエブページを壊さない為の意図的な挙動だったりするのかしら。p のタグを「大きい br」みたいに捉えてるページが存在して、段落を跨ぐ形でインライン要素を使ってる事があるとしたら。
@ara_tsuma そうそう。見るだけでも、お気に入りしたい時にできるし。
カスタム絵文字は前後が普通の文字に接してると駄目で、空白や改行や句読点で区切る必要があります。右下のメニューから「編集」で試してみて。

@sayunu そこらへんのパーサーの挙動はWHATWGの HTML Living Standard 仕様で操作的に定義されているんですよね。
HTML Living Standard 13.2 Parsing HTML documents
そこの Note に、なんでそうなっているのかが書いてあります。
While the HTML syntax described in this specification bears a close resemblance to SGML and XML, it is a separate language with its own parsing rules.
Some earlier versions of HTML (in particular from HTML2 to HTML4) were based on SGML and used SGML parsing rules. However, few (if any) web browsers ever implemented true SGML parsing for HTML documents; the only user agents to strictly handle HTML as an SGML application have historically been validators. The resulting confusion — with validators claiming documents to have one representation while widely deployed web browsers interoperably implemented a different representation — has wasted decades of productivity. This version of HTML thus returns to a non-SGML basis.
Authors interested in using SGML tools in their authoring pipeline are encouraged to use XML tools and the XML serialization of HTML.
昔のHTMLは、仕様上はSGMLによって構文解析ルールが規定されていましたが、SGMLは複雑で、ブラウザーは仕様通りにちゃんと実装することはなかったんですよね。今はHTMLの仕様はSGMLと無関係に仕様が決まっていて、結果的に、昔からのブラウザーの挙動を再現しつつ、ブラウザー間の挙動を統一するものになっています。
@mandel59 おおー  ちゃんと読んでないけど、今では相互運用可能になるように定義されてるようですね。ありがとうございます。
ちゃんと読んでないけど、今では相互運用可能になるように定義されてるようですね。ありがとうございます。
#Mastodon のタイムライン内に添付画像をどんな風に表示するかについては、幾つか観点がある。
(1) そもそもタイムラインに文字以外を表示したいかどうか
(2) 見たい画像かどうか
(3) 見やすい体裁かどうか
まづ (1) について。「タイムラインは飽くまで文字重視でコンパクトに表示し、見たい画像があれば個別に展開したい」という利用者がいる。この場合、常に小さいサムネイルだけ表示するのが望ましいだろう。
(2) について。フォロー対象のアカウント別に「この人のブーストは表示しない」という設定が可能なら、「この人の画像は大きく表示したい」などの設定項目があってもいい。
以前「ホームタイムライン内では画像を大きく、連合では小さく表示したい」との声があった。タイムラインの役割として見るなら (1) で、アカウントの種類として見るなら (2) に近いかしら。
(3) について。大きく表示したいとしても、表示領域の広さや画像の内容に依って見やすい大きさは異なる。現状は「横幅をカラムいっぱいにして、縦幅は成り行き」という単純な作りになっていて、必ずしも最適ではない。
table‐関連の HTML‐要素を使っていても、CSS で display の値を変えると意味論が変わる(表という意味を失う)らしい。どうしてそんな事になってしまったんでしょうか。スタイルシートは見た目に過ぎず、マークアップが適切であれば根底の意味を維持するというのが十年前の認識だったと思うけど…。どのようにスタイルされるかを見越してマークアップに ARIA role を書き加える必要があるって何事 ? #HTML #CSS
https://developer.mozilla.org/en-US/docs/Web/Accessibility/ARIA/Roles/cell_role

@tizerm 〈キロ〉は飽くまで「千」と定義されているが、計算機分野の人々が 1024 の意味で使い始めて混乱したので、ちゃんと使い分けましょうという事で 1024 の為に〈キビ〉などの接頭辞を折角用意したのに、相変わらず厳密に使わない販売者が多いから混乱が続いているという状況。「そう表示している製品がある」というのはまさに混乱の表れだ。
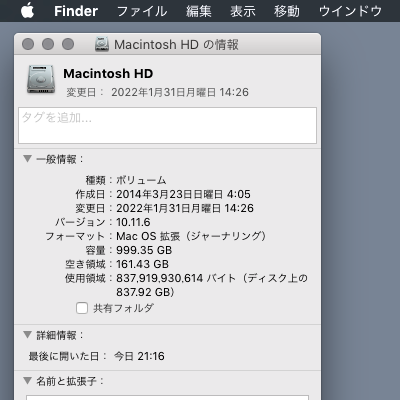
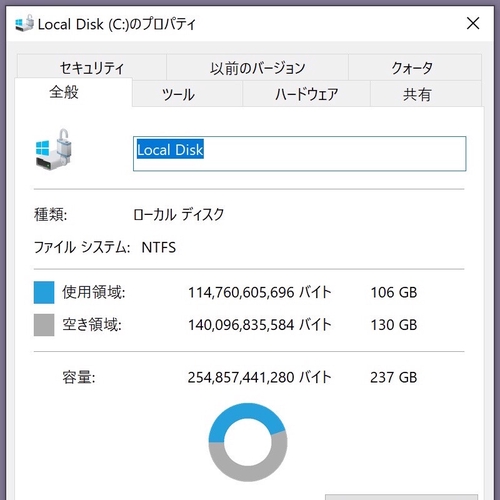
Mac のシステムは記憶容量について、1000³ バイトの意味で「1 GB」と表示する(四捨五入)。社用機を見ると、Windows 10 は 1024³ バイトの意味で「1 GB」と表示しているようだ(切り捨てかしら)。
@tizerm 日本人ですよ、多分…ページの下部の「翻訳 README」のリンクを踏み、「翻訳チーム」の節の「日本語」を開き、「View Members」で輝かしい翻訳者一同のお名前が見られる。「翻訳にあたってのポリシー : 逐次訳です。追跡可能であることが大事です」だそうだ。
@tizerm 日本語を喋る日本人のくせに自然な日本語を書かないでタスク完了にする人嫌い。日本語について深く自問しないで方針・理念を言い訳にする人嫌い。原文への忠実さを自称して結果的に読者から見た当該文書への印象を悪くする人嫌い。
訳さないで片仮名で書くと「レッサー一般公衆ライセンス」になるから、それはそれで問題がある。何が悪いかというと、〈劣等〉という語を当てる判断が良くない。劣等パンダと優等パンダか ?
@tizerm その例は主に〈‐er〉に直接対応する日本語の表現がないのが翻訳に頭を使うべき所で、「交叉を観測する」までは理解を阻む要因がない。現代日本語が造語能力をひどく失っているのは確かだけど。
@tizerm 〈‐er〉が人に限らないのは元からで、機械も器具も物質も ‐er だ。日本語では〈‐機〉〈‐器〉〈‐体〉〈‐子〉などと言ったりする。抽象性の高いプログラミング概念の listener とか observer とかが訳しにくい。この例では「API」って付ける限りは「重なり監視 API」などでいい気もする。
拡大より縮小の方が作りやすいだろうから、まづは東雲 16 か出水を元にして、一画素づつ縮小した物を整えていくのが効率がいいんぢゃないかな。

このアカウントは、notestockで公開設定になっていません。
「The vowel space」
https://www.englishspeechservices.com/blog/the-vowel-space/
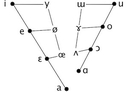
「母音台形」を三角形に描くのすごい納得感があるなあ。(というかアを前か後ろに分けないといけないのが元々釈然としなかったもん。)台形の図は真ん中辺りがゴチャゴチャし過ぎというのも共感する。
ただ第三フォルマントを捨象するのが妥当かはよく分からない。この図は三次元空間を二次元に投影した物と見るべきぢゃないかしら。で、真ん中辺の記号の張り合いを再整理してある。
「ベビー・ボックス」のほかに「ママ・ボックス」が出て来たの面白かったし、クシャミやシャックリを植えてクシャミやシャックリの花が咲くという発想が面白かった。
まだ画像を載せてなかったので…こちらが「M+」の漢字ビットマップ。それぞれ 10 画素と 12 画素(字面はほぼ「9 × 9」と「11 × 11」、但し縦線が上へ突出する)。


Colemak で 54 wpm が出た。
Monkeytype に集中して打つぞという時はいいけど、作業の流れの中でラテン文字を少し入力する場面ではまだ安定しない。
日本語を書く時は全く別の配列を使うから、ラテン文字の配列を切り替えた直後でもあまり生産性に影響がないのが強み。その反面、そこそこ打てるようになったあと「実用しながら慣らしていく」事があまりできないという課題がある。しばらくローマ字入力にする…?
56 wpm が出た。
Colemak を使うのが合理的な選択だと思ってるわけではなく…どれぐらい移行しやすいか、どれぐらい打ちやすいか試してやるくらいの目的で触ってる。それを判断するには打てるようにならないといけない。
主に日本語を話す人には、日本語入力の方法だけ弄るのを勧めたい。英語を喋りまくりたいんでなければ、英字の入力は QWERTY のままでいいだろう。やはり他人のパソコンを触る時とか、ショートカットの配置とかの課題があって、それを乗り越える程の利点は見出だしにくい。
日本語の仮名入力は、少なくとも私の経験では英字配列の慣れとほとんど干渉しない。「他人のパソコン」で一時的にローマ字入力をする必要がある場合も「しましたぢゃなくて simasita ね…」と意識しながら、少し遅くなっても あまり混乱しないで打てる。
「仮名配列を覚えるのは気が引ける」という人がいる場合…英字直接入力を QWERTY で行い、日本語を QWERTY‐以外でローマ字入力するのが認知的にどんなもんかは知らない。ローマ字を基礎にしない行段式の仮名入力方式(「カ行」「イ段」というキーがあって「K」と「I」そのものではない奴)が、ローマ字式と別扱いで脳に収まるかどうかも気になる所。



