3つ目の文字を入れるならおそらくデーヴァナーガリーかアラビア文字

Google Operating System: Tweak Google Chrome's Translation Feature http://googlesystem.blogspot.com/2010/03/tweak-google-chromes-translation.html
古のGoogle翻訳情報


このアカウントは、notestockで公開設定になっていません。
別に独自に考案せずとも、既にリポジトリに登録されている内容だけでかなだけならja-Hrkt、漢字かな混じりならja-Jpan(これはわざわざやる必要はない)のようなタグ付けが考えられます。RFC 5646およびISO 15924を参照
ja-Jpanに関しては、アメリカ英語を指すためにen-USではなくen-US-Latnと書いても有益な情報は増えないのに表記揺れが起きるのと同じ話
IETF言語タグの各部分は基本的にISO 639の言語コード、ISO 15924の文字体系コード、ISO 3166-1の国コードなどを参照しているのでそれらを見ると色々面白い
ISO 3166-2:JP - Wikipedia https://ja.wikipedia.org/wiki/ISO_3166-2:JP
皆なんとなく知っている都道府県の番号(実はJIS規格で振られている)もちゃんと国際規格に反映されている

@keizou en-Latn-US(私の先程の表記はIETF言語タグの正しい語順ではありませんでした、ごめんなさい)のような表記は "(...) the script subtag SHOULD be omitted when it adds no distinguishing value to the tag or (...)"(RFC 5646, Section 2.2.3, p.13)に該当すると考えています。
また、仮にこのSHOULDとそもそも文字体系のサブタグは必須でないという点を無視するとしても、これまでメタデータにつけられたjaやja-JPを捨てずに処理するならja-Japnやja-Japn-JP相当だということになります。
@keizou なので、ja-Hiraのようなタグは恐らく良いものですが、文字体系コードを必須にすることは必要な作業に見合わないと考えます
@keizou IANAのLanguage Subtag Registryを確認したらjaに対して "Suppress-Script: Jpan" が指定されているので、先程省略した "the script subtag SHOULD be omitted (...) when the primary or extended language subtag's record in the subtag registry includes a 'Suppress-Script' field listing the applicable script subtag." に該当する明示的な非推奨パターンでした。無視に関する私の意見は先程と同じです
@keizou まぁ、メタデータをどう書くかという土台は既にあるので、コンテンツを作る人々に周知され、ツールや環境が整備されるかどうか次第だと思います
@keizou 別にエンコーディングは変わらないのでそこは心配ないと思います
UTF-16以前からUnicodeには合成文字の概念があったので、単に16ビット固定長で「1文字」と考えていた人々が仕様を把握していなかった説がある

Unicode 、実のところ U+10FFFF までしか使われないのでコードポイントとしては 21 bit で済むし、 UTF-32 は無駄すぎる
unicode - Why is there no UTF-24? - Stack Overflow
https://stackoverflow.com/a/10143909
ハイ

内部保持形式としては 4byte だとアライメントで問題が発生しないとかでマシそうって言おうとしたらやっぱりそう
漢字統合して、予備の漢字用領域も用意しとけばよくね?←……よくなかったね……
2バイトで1文字だ!←結合文字はUnicode 1.0にもあるのでそんなことは割と最初からなかった
Ideographic Rapporteur Group - Wikipedia https://ja.wikipedia.org/wiki/Ideographic_Rapporteur_Group
CJK統合漢字は非漢字圏ではなく(各国内規格を別々に符号化すると自国分が不足すると危惧した)中国が推してたという話はWikipediaの複数ページに書かれているんだけれども、誰でも参照できるところに議事録とか残ってないんだろうか(それが参考文献にないので真偽が謎)

このアカウントは、notestockで公開設定になっていません。

このアカウントは、notestockで公開設定になっていません。

このアカウントは、notestockで公開設定になっていません。

@mzp 単に「なんたらかんたら - Single」な曲もあるので、スマートプレイリストを作ってそれを条件にクエリをかけるのが一番便利
@mzp 基本的には
- アルバムに「THE IDOLM@STER」が入ってるか
- タイトルに「M@STER VERSION」が入ってるか
で判定して、漏れたのはアーティスト欄をアイドル名で検索…
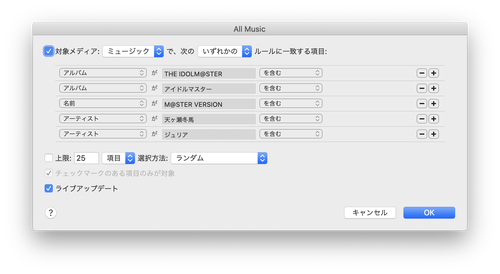
@mzp これとか、アーティスト欄にしかアイマス判定able要素がない https://music.apple.com/jp/album/beyond-the-dream-ep/1196631527


repeat with aTrack in (every file track of playlist 1 whose album contains "CINDERELLA" or album artist contains "CINDERELLA" or artist contains "CINDERELLA")
@mzp デレステのイベントが楽曲の初出なのでSTARLIGHT M@STERになるはずだが、まだ採番がされてないので先行配信ではシングルアルバムとして売られてるやつ(クレイジークレイジーなど)
O'Reilly Japan - Books :: Hacks https://www.oreilly.co.jp/books/hacks/
『Blog Hacks』とか抜けてるから確信は持てないけれど本当に最新は『Android KitKat Hacks』なのだろうか
Ensemble Pulsar Time Scale - ScienceDirect https://doi.org/10.1016/j.chinastron.2017.08.010

このアカウントは、notestockで公開設定になっていません。
このアカウントは、notestockで公開設定になっていません。

このアカウントは、notestockで公開設定になっていません。

このアカウントは、notestockで公開設定になっていません。
LibreSSLのTLS 1.3サポートがもう少しで有効化されそうな気配がある
rust.tokyo のまとめ・感想 - mizchi's blog https://mizchi.hatenablog.com/entry/2019/10/27/022804


このアカウントは、notestockで公開設定になっていません。



